자연어 처리 뿐만 아니라 최근 컴퓨터 비전 영역에서도 사용되고 있는 유명한 모델인 Transformer를 알아보도록 하겠습니다. Attention Is All You Need The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new arxiv.org 트랜스포머는 2017년 구글에서 발표한 논문으로, Attent..
이미지 분야에 Transformer 구조를 적용한 아키텍쳐를 제시한 논문인 ViT에 대해 정리하고자 합니다. ViT는 구글에서 발표한 논문으로, 기존에 자연어 처리 분야에서 널리 사용되고 있는 트랜스포머를 비전 분야에 적용함으로써 SOTA의 성능을 보인 논문입니다. 이 모델 자체는 엄청나게 많은 양의 데이터로 Pre-train 해야 한다는 단점은 있지만, 어쨋든 높은 성능을 보인다는 점과, 비전 분야에 트랜스포머를 성공적으로 적용한 논문이라는 의의가 있습니다. Architecture ViT는 다음과 같은 구조로 이루어져 있습니다. 이 아키텍쳐를 기준으로 어떻게 동작하는지를 설명해보도록 하겠습니다. Patch, Embedding ViT는 이미지가 들어왔을 때, 먼저 여러개의 Patch로 자르는 작업을 실행..
기존 CNN 모델들의 경우 고성능 컴퓨터에서는 이를 연산할 만한 충분한 컴퓨팅 자원들이 있었지만 스마트폰이나 기타 기기에서 사용하기에는 너무 무겁다는 단점을 가지고 있었습니다. 구글은 이러한 문제를 해결하기 위해 Mobilenet을 개발하였으며, 성능을 최대한 희생하지 않으면서도 모바일 환경에서 구동될만큼 경량화 한 것이 특징입니다. 이번 페이지에서는 Mobilenet V1의 핵심 아이디어 Depthwise Separable Convolution을 간략하게 정리하고, Mobilenet V2, 이 모델의 핵심 아이디어인 Inverted Residuals, Linear Bottlenecks를 정리하도록 하겠습니다. Depthwise Separable Convolution Mobilenet V2를 이해하기 전..
이전 페이지에서는 Transformer가 무엇인지 이론을 확인할 수 있었습니다. 이번 페이지에서는 Transformer를 구현해보도록 하겠습니다. [논문 리뷰] Transformer 리뷰 자연어 처리 뿐만 아니라 최근 컴퓨터 비전 영역에서도 사용되고 있는 Attention이라는 기법을 적용한 유명한 모델인 Transformer를 알아보도록 하겠습니다. Transformer 트랜스포머는 2017년 구글에서 발 dyddl1993.tistory.com Transformer class Transformer(nn.Module): def __init__(self, N = 2, hidden_dim = 256, num_head = 8, inner_dim = 512): super().__init__() self.enco..
자연어 처리 뿐만 아니라 최근 컴퓨터 비전 영역에서도 사용되고 있는 Attention이라는 기법을 적용한 유명한 모델인 Transformer를 알아보도록 하겠습니다. Transformer 트랜스포머는 2017년 구글에서 발표한 Sequence to Sequence 모델입니다. 이 모델을 통해 이전 모델의 단점들(고정된 Context Vector, 첫 레이어의 결과값이 연산을 반복하면서 희미해짐 등)을 해결하게 되었습니다. 모델의 특이점으로는 RNN, CNN등의 레이어를 사용하지 않았다는 점, Attention이라는 개념을 사용했다는 점 정도가 있습니다. Encoder Input input값으로 임베딩 된 벡터를 사용하는 것은 기존의 방법들과 같다고 할 수 있지만, 이 값에 더해 추가로 Positional..
기존의 딥러닝 기반 얼굴 인식 연구는 두 가지 방법으로 정리할 수 있습니다. 첫번째 방식은 softmax loss를 사용하는 방식으로 분류 모델을 softmax를 통해 훈련하는 방식입니다. 두번째는 triplet loss를 사용하는 방식인데 이 방식은 분류 모델을 학습하는 것이 아닌 임베딩 벡터를 학습하는 방식입니다. 저자들은 두 loss 모두 단점이 몇 가지 존재한다고 설명합니다. softmax loss의 경우 가지고 있는 훈련 데이터셋에 적합한 학습을 하기 때문에 open-set에는 적합하지 않다고 설명을 하고 있는데, 이는 쉽게 말해 새로운 인물에 대해서는 적절한 feature를 추출하지 못하는 단점을 가지고 있다고 보시면 됩니다. triplet loss의 경우 학습에 어려움이 있다는 점과, fac..
이제 이미지나 자연어 등의 비정형 데이터에 대해서는 딥러닝을 기반으로 한 연구만이 진행되고 있다고 봐도 무방합니다. 다만 정형 데이터에 대해서는 아직도 머신러닝 모델, 특히 트리 기반의 부스팅 계열 모델들의 성능이 더 뛰어납니다. 제가 참여했던 프로젝트에서도 정형 데이터에 대한 모델링을 수행할 때는 일반적으로 LightGBM 등 머신러닝 계열 모델의 성능이 딥러닝 모델들보다 조금 더 좋은 결과를 보여주었습니다. 대표적으로 LightGBM, XGBoost, CatBoost 등의 모델이 있는데, 이 모델들은 아직까지도 정형 데이터를 사용하는 경진대회에서 상위권을 차지하고 있을 만큼 성능이 좋습니다. 하지만 최근 들어 TabNet이라는 딥러닝 모델이 가끔씩 대회에서 등장하고 있습니다. 이 모델은 저자들의 테스..
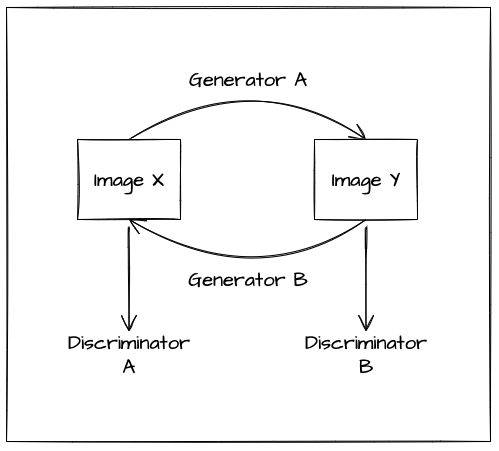
CycleGAN 이란 CycleGAN은 Style Transfer 분야에 GAN을 적용시킨 대표적인 모델입니다. Unpaired Image-to-Image Translation using Cycle-Consistent... Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pai..
DCGAN(Deep Convolutional GAN)은 GAN의 대표적인 모델로써, GAN에 컨볼루전망을 적용하여 성능을 향상시킨 모델입니다. 간단하게 DCGAN에 대해 설명한 후 실습과 함께 상세하게 알아보도록 하겠습니다. DCGAN 요약 DCGAN은 2016년에 발표된 모델로 GAN의 가장 대표적인 모델입니다. https://arxiv.org/abs/1511.06434 Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks In recent years, supervised learning with convolutional networks (CNNs) has seen huge adoption ..
딥페이크 라는 단어를 들어보신 적 있으신가요? 딥페이크는 영상 속 사람 위치에 임의의 다른 인물을 합성하는 가짜 영상을 말합니다. 위의 영상은 딩고 뮤직 배경에 일론 머스크의 얼굴을 합성하고, SG워너비 살다가 음악을 임의의 음성으로 변형한 대표적인 딥페이크 영상입니다. 이러한 가짜 영상을 생성해내는 모델들 중 하나가 이번에 소개드릴 GAN이라는 모델입니다. 간단하게 GAN이 무엇인지, 어떻게 동작하는지, 어떠한 한계점이 있는지에 대해 설명해보겠습니다. GAN 이란 GAN은 겐 또는 간으로 불리며, 주로 겐으로 읽는다고 합니다. 제 주변에서는 둘 다 많이 읽히고 있습니다. Generative GAN의 첫 글자인 G는 Generative의 줄임말입니다. 이 단어에서 알 수 있듯이 GAN은 무언가를 생성하는..