
자연어 처리 뿐만 아니라 최근 컴퓨터 비전 영역에서도 사용되고 있는 Attention이라는 기법을 적용한 유명한 모델인 Transformer를 알아보도록 하겠습니다.
Transformer
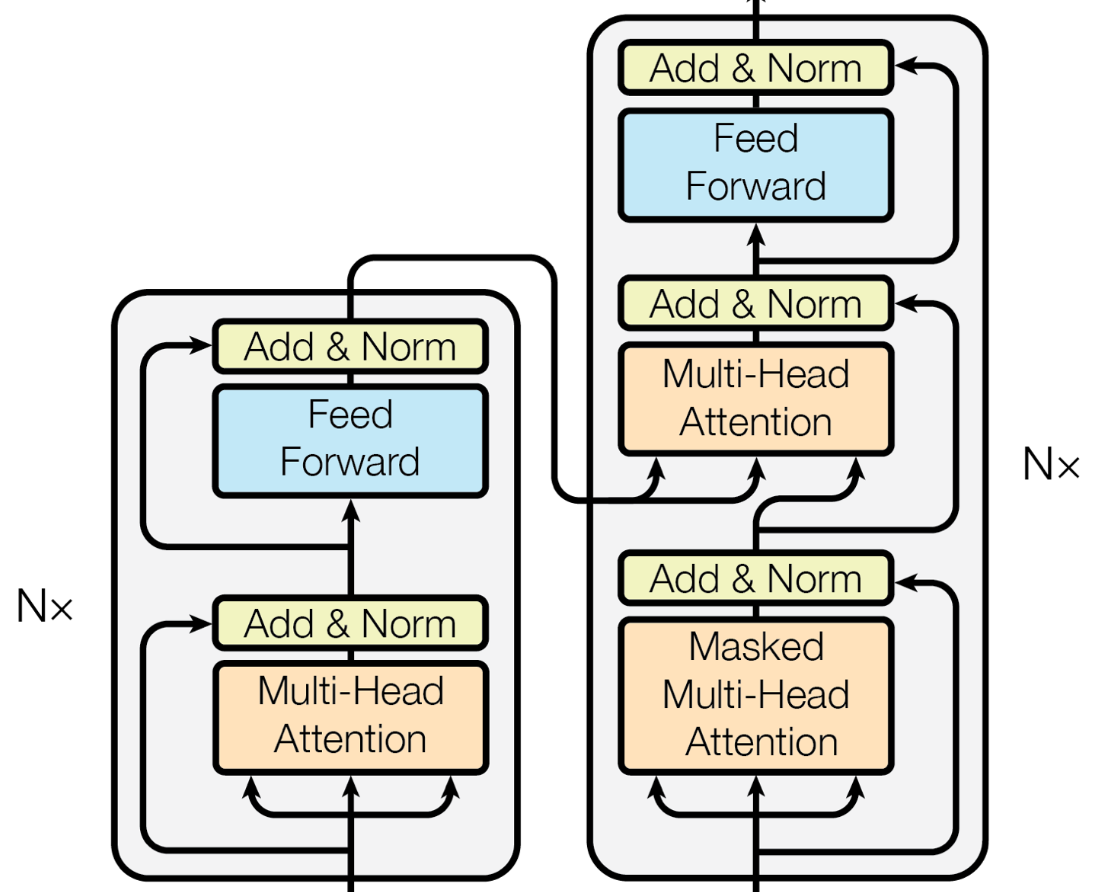
트랜스포머는 2017년 구글에서 발표한 Sequence to Sequence 모델입니다. 이 모델을 통해 이전 모델의 단점들(고정된 Context Vector, 첫 레이어의 결과값이 연산을 반복하면서 희미해짐 등)을 해결하게 되었습니다.
모델의 특이점으로는 RNN, CNN등의 레이어를 사용하지 않았다는 점, Attention이라는 개념을 사용했다는 점 정도가 있습니다.
Encoder
Input
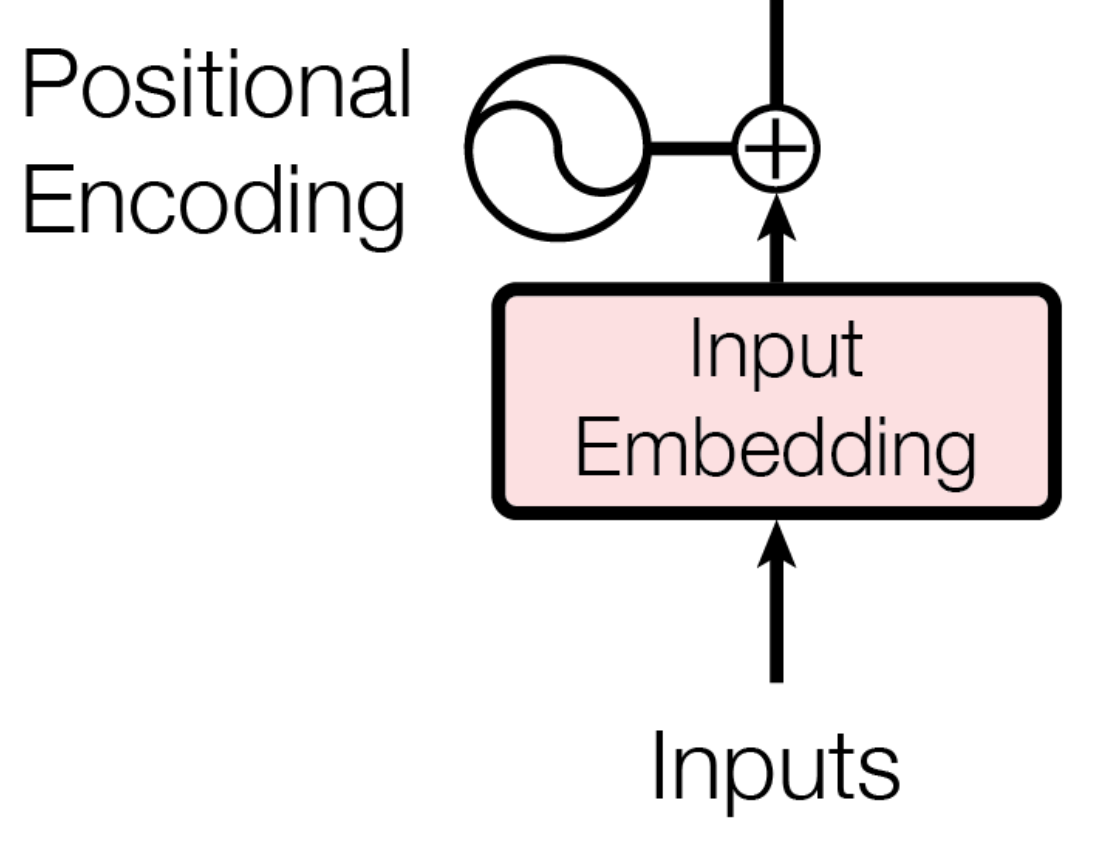
input값으로 임베딩 된 벡터를 사용하는 것은 기존의 방법들과 같다고 할 수 있지만, 이 값에 더해 추가로 Positional Encoding이라는 방법을 사용하여 임베딩 된 값들에 위치 정보를 더해주는 방식을 사용하고 있습니다.
Positional Encoding
주기 함수를 사용하여 단어의 상대적인 위치를 입력하는 방식입니다.
Architecture
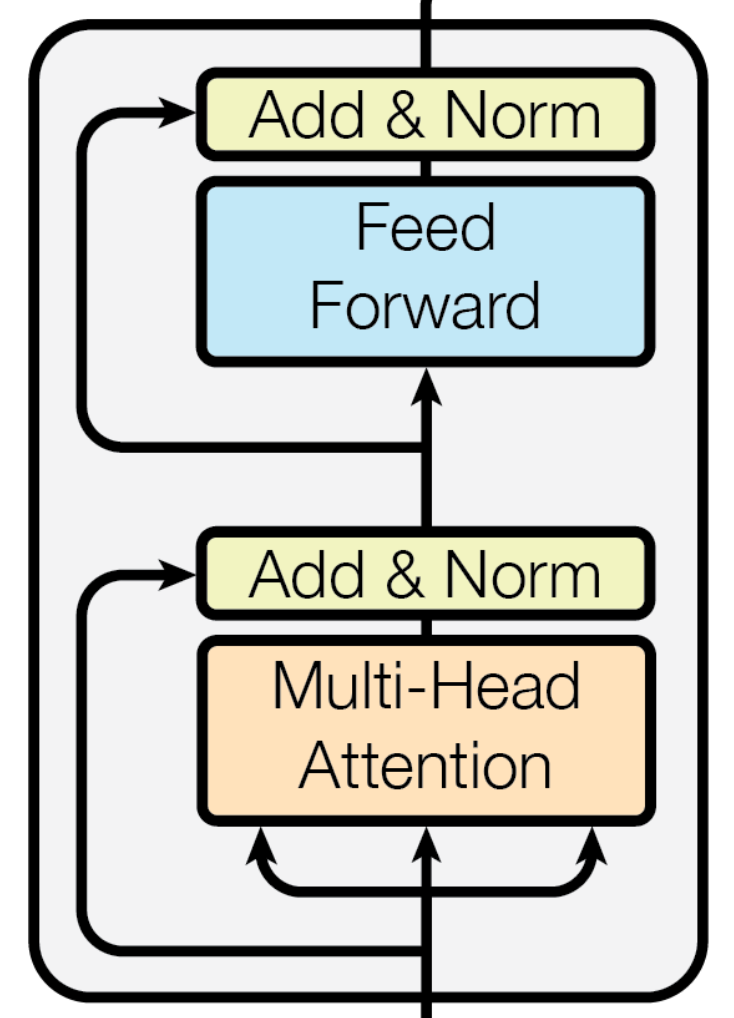
Multi-Head Attention이라는 모듈을 사용하는데, Attention에 대해서는 뒤에 설명하도록 하겠습니다.
Add & Norm의 Add는 Residual connection(또는 Skip connection)입니다. Norm은 Layer Normalization을 사용합니다. LayerNorm에 대한 설명은 하기 링크로 대체하겠습니다.
https://yonghyuc.wordpress.com/2020/03/04/batch-norm-vs-layer-norm/
Feed Forward는 Linear한 연산입니다. 간단하게 FC - RELU - Dropout - FC 로 구성되어 있습니다.
Decoder
Architecture
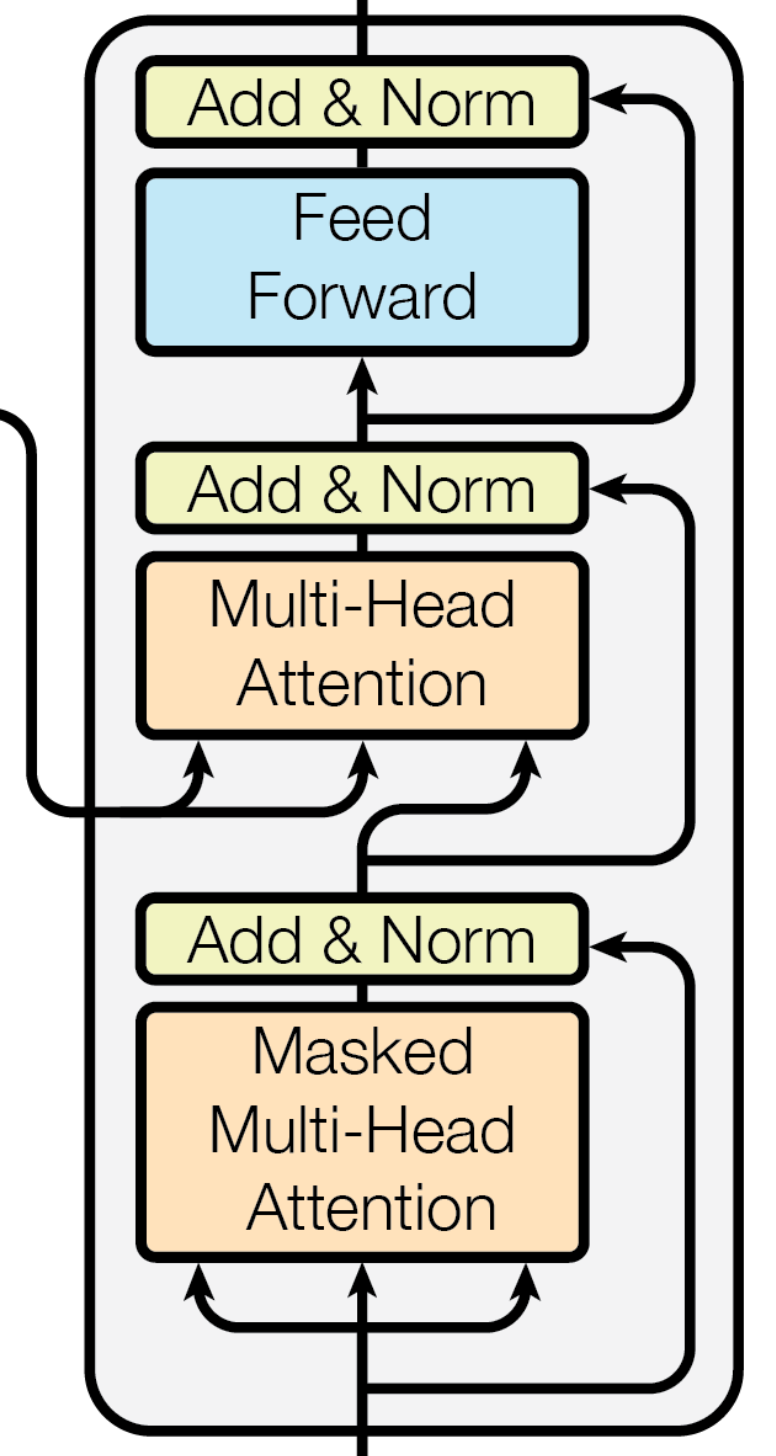
Multi-Head Attention을 사용하는데, 디코딩 시에 미래 시점의 정보를 제한하기 위해 Masked Self Attention을 사용하고 있습니다. 또한 아키텍쳐 중앙 부분을 보시면 인코더가 보내온 정보를 받아 기존 디코더 연산과 함께 멀티 헤드 어텐션을 수행하는 것을 확인하실 수 있습니다. 참고로 디코더에서 이 부분을 뺀 아키텍쳐가 바로 GPT에서 사용하는 아키텍쳐입니다.
Output
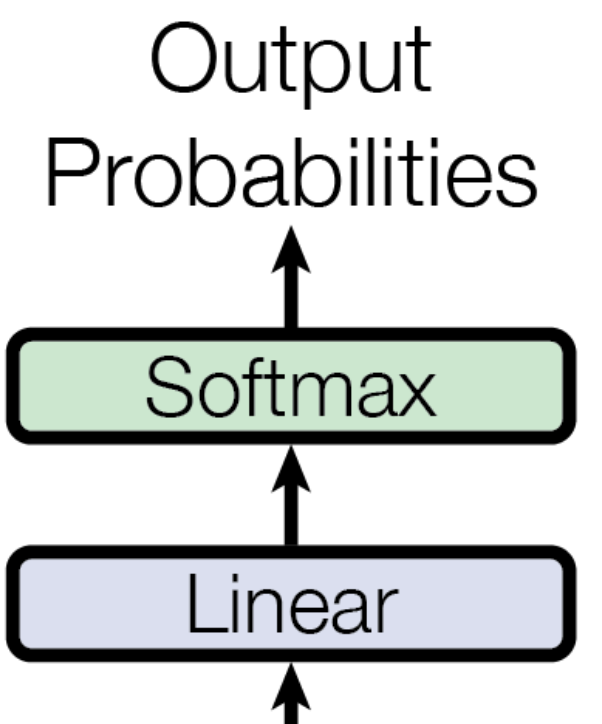
위의 아키텍쳐에서 나온 결과는 Linear - Softmax 연산을 통해 최종 확률값을 출력합니다.
Attention
Attention
트랜스포머에서는 대부분 Self Attention이라는 개념을 사용하고 있습니다. 다만 아키텍쳐 상 딱 한 부분만 Attention을 사용하고 있는데 아래 그림과 같이 encoder, decoder 각각에서 input값이 들어오는 걸 확인할 수 있습니다. 정확하게는 디코더의 마지막 어텐션은 K,V 부분은 encoder에서, Q부분은 decoder의 이전 output에서 가져오고 있습니다.
Attention과 Self Attention의 차이에 대한 설명은 아래 블로그에 자세히 적혀 있습니다. https://velog.io/@idj7183/Attention-TransformerSelf-Attention
Self-Attention
Self-Attention은 Query, Key, Value 간의 관계성을 추출하는 과정으로 볼 수 있습니다. Query는 현재 시점의 토큰 값을, Key와 Value는 Attention을 통해 찾고자하는 토큰 값이라고 이해할 수 있습니다.
입력 벡터 시퀀스(X)에 대해 각각의 가중치 벡터를 곱함으로써 Query, Key, Value를 생성합니다. 이 가중치들은 학습을 통해 업데이트 되는 파라미터들입니다.
$$
Q = XW_Q\\
K = XW_K\\
V = XW_V
$$
셀프 어텐션은 각각의 쿼리 $Q$에 대해 다음과 같은 수식을 적용하여 구할 수 있습니다.
$$
Attention(Q,K,V) = softmax({QK^T\over{\sqrt{d_K}}})V
$$
이때의 $d_K$ 는 임베딩 차원을 의미합니다. $\sqrt{d_K}$ 로 나누면서 Vanising Gradient 등을 방지합니다.
그림으로 간단하게 셀프 어텐션을 표현해보도록 하겠습니다.
글자 길이 수 n = 2, 입력값으로 들어온 단어 임베딩 차원 = 3, 벡터 임베딩 차원 $d_K$ = 4라고 가정하고 임의의 Query를 다음과 같이 생성해 보겠습니다. 구조만 확인하는 것이므로 값은 모두 0을 넣었습니다.
글자 길이가 2, Input Embedding 차원이 3이므로 $X$의 shape는 다음과 같습니다.
$$
X =
\begin{bmatrix}
0 & 0 & 0\\
0 & 0 & 0\\
\end{bmatrix}
$$
이에 대해 벡터 임베딩 차원이 4이므로 $W_Q, W_K, W_V$의 shape는 다음과 같습니다.
$$
W_Q =
\begin{bmatrix}
0 & 0 & 0 & 0\\
0 & 0 & 0 & 0\\
0 & 0 & 0 & 0
\end{bmatrix}
$$
이 둘을 연산한 Query는 다음과 같습니다.
$$
Q = XW_Q = \begin{bmatrix}
0 & 0 & 0\\
0 & 0 & 0\\
\end{bmatrix}\begin{bmatrix}
0 & 0 & 0 & 0\\
0 & 0 & 0 & 0\\
0 & 0 & 0 & 0
\end{bmatrix}
=
\begin{bmatrix}
0 & 0 & 0 & 0\\
0 & 0 & 0 & 0\\
\end{bmatrix}
$$
$K, V$도 Query처럼 2x4일 것입니다. 이제 $QK^T$를 구해보도록 하겠습니다.
$$
QK^T=\begin{bmatrix}
0 & 0 & 0 & 0\\
0 & 0 & 0 & 0
\end{bmatrix}
\begin{bmatrix}
0 & 0\\
0 & 0\\
0 & 0\\
0 & 0
\end{bmatrix}
=
\begin{bmatrix}
0 & 0\\
0 & 0
\end{bmatrix}
$$
$QK^T$는 2x2 행렬입니다. 이에 대해 Softmax를 적용하고 Value를 곱해준 최종적인 shape는 2x4입니다. $\sqrt{d_K}$ 는 스칼라 값이므로 shape에는 영향을 주지 않습니다.
$$
softmax(QK^T)V=\begin{bmatrix}
0 & 0\\
0 & 0
\end{bmatrix}
\begin{bmatrix}
0 & 0 & 0 & 0\\
0 & 0 & 0 & 0
\end{bmatrix}
=
\begin{bmatrix}
0 & 0 & 0 & 0\\
0 & 0 & 0 & 0
\end{bmatrix}
$$
즉 결과값이 input값과 shape이 동일한 것도 확인하실 수 있습니다.
Multi-Head Attention
Self-Attention을 여러 번 수행한 것을 Multi-Head Attention이라고 합니다. 다음과 같은 수식으로 정리할 수 있습니다.
$$
MultiHead(Q,K,V) = concat([head_1, head_2, ..., head_h)W^o
$$
여기서 $head_i$ 는 i번째 $Attention$을 의미합니다.
마지막에 곱해주는 $W^o$의 크기는 Concat한 Self-Attention의 컬럼 길이 * 목표 차원수이며, $W^o$의 값은 learnable parameter입니다.
Masked Multi-Head Attention
디코딩 하는 시점에서 미래 시점의 정보를 알지 못하도록 미래 시점의 가중치를 0으로 마스킹 하는 방법을 사용합니다. 구체적으로는 softmax를 적용하기 직전에 mask를 하고자 하는 토큰에 대해 -inf를 더하거나 치환함으로써 softmax 후 해당 가중치가 0이 되게끔 작업을 합니다.
굳이 이렇게 하는 이유는 행렬 연산의 이점을 그대로 가져가면서도 masking을 하기 위함으로 보입니다.
Masking
지금까지 아키텍쳐에서 Masked Multi-Head Attention이라는 블록을 확인했습니다. Transformer에서는 두 가지 마스킹 방법을 사용하고 있는데, 어떤 방법이 있는지, 어떻게 동작하는지 살펴보도록 하겠습니다.
Padding Mask
input으로 들어오는 sentence의 길이는 서로 다를 가능성이 높습니다. 때문에 이러한 문장 길이를 동일하게 맞춰주는 작업이 필요하다고 할 수 있습니다. 이럴 경우 가장 긴 문장을 기준으로 짧은 문장의 뒤에 0을 마스킹해서 길이를 맞춰주는 과정이 필요합니다. 이러한 과정을 Padding이라고 하고, 이를 위한 마스킹을 Padding Masking이라고 합니다.
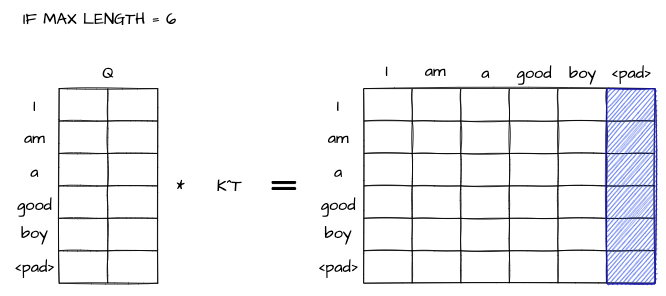
위의 그림을 보고 다시 설명을 해 보도록 하겠습니다. 참고로 보통 a는 전처리 단계에서 많이 제거합니다 만 약 최대 길이기 6일 때 길이가 5인 문장이 들어온다면 마지막 단어에 대해서는 Attention이 계산되지 않아야 합니다.
파란색 박스 영역 위치의 값에 대해 -inf를 넣어준다면, 이후 softmax 연산을 통해 해당 위치의 Attention을 0으로 만들 수 있습니다. 이러한 작업을 하기 위치를 찾아주는 방법이 Padding Mask입니다. 이 마스킹 방법은 Encoder, Decoder 모두 사용됩니다.
Look-ahead masking
Masked Multi-Head Attention에서만 사용되는 마스킹 방법입니다. 디코더의 입력에 미래 시점의 단어가 들어가지 않게 하기 위한 마스킹이라고 볼 수 있습니다. 따라서 다음과 같은 그림으로 구현을 해야 합니다.
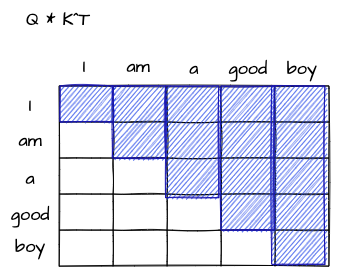
눈치채셨겠지만, 디코더의 Masked Multi-Head Attention에서도 당연히 Padding Masking도 사용하기 때문에 pad가 존재한다면, 최종적으로 마스킹 된 부분은 다음 그림처럼 표현이 됩니다.
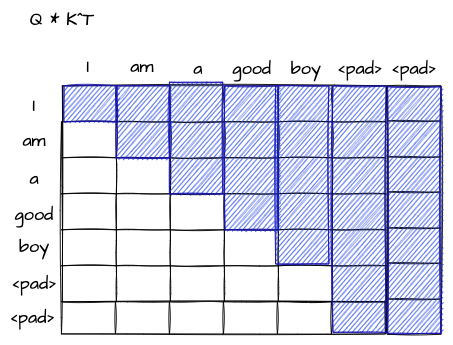
참고
https://velog.io/@idj7183/Attention-TransformerSelf-Attention