
이전 페이지에서는 Transformer가 무엇인지 이론을 확인할 수 있었습니다. 이번 페이지에서는 Transformer를 구현해보도록 하겠습니다.
[논문 리뷰] Transformer 리뷰
자연어 처리 뿐만 아니라 최근 컴퓨터 비전 영역에서도 사용되고 있는 Attention이라는 기법을 적용한 유명한 모델인 Transformer를 알아보도록 하겠습니다. Transformer 트랜스포머는 2017년 구글에서 발
dyddl1993.tistory.com
Transformer
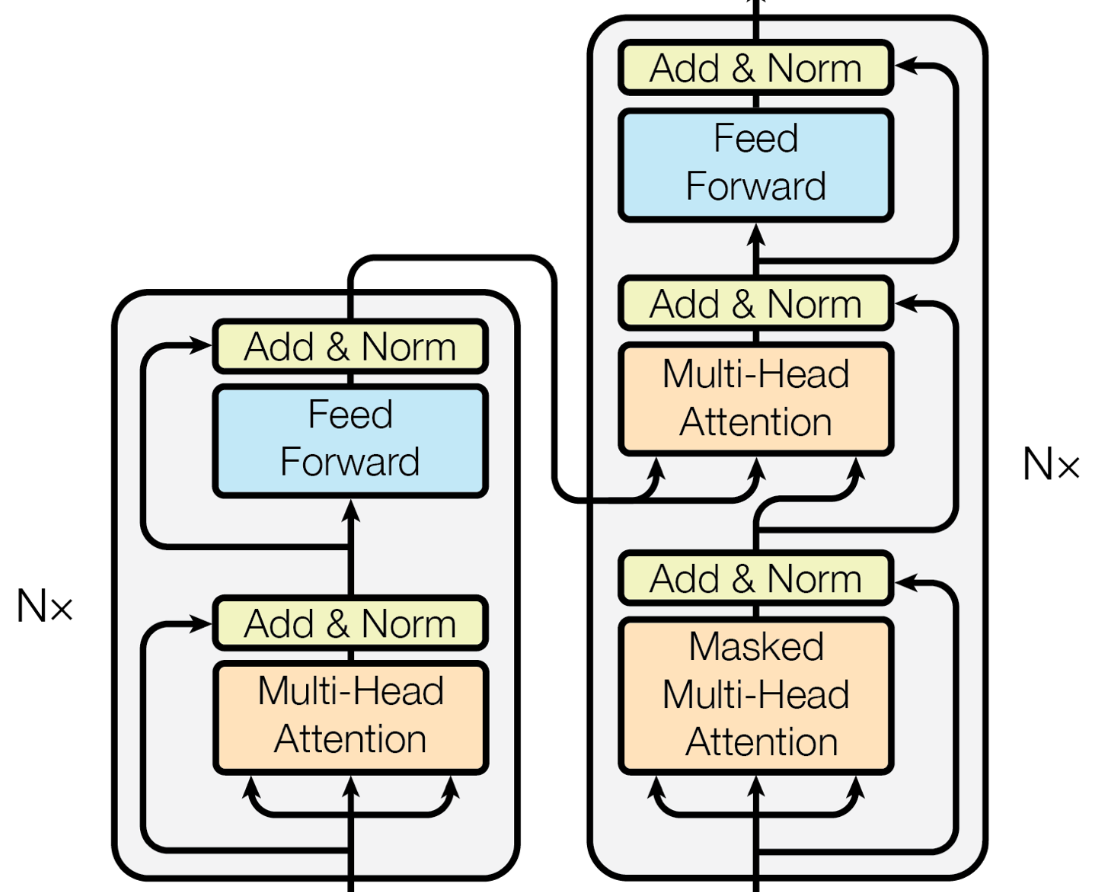
class Transformer(nn.Module):
def __init__(self, N = 2, hidden_dim = 256, num_head = 8, inner_dim = 512):
super().__init__()
self.encoder = Encoder(N, hidden_dim, num_head, inner_dim)
self.decoder = Decoder(N, hidden_dim, num_head, inner_dim)
def forward(self, enc_src, dec_src):
enc_output = self.encoder(enc_src)
logits, output = self.decoder(dec_src, enc_src, enc_output)
return logits, output
아키텍쳐 그림과 같이 decoder가 dec_src, enc_src, 그리고 enc_output을 받도록 설정합니다.
Encoder
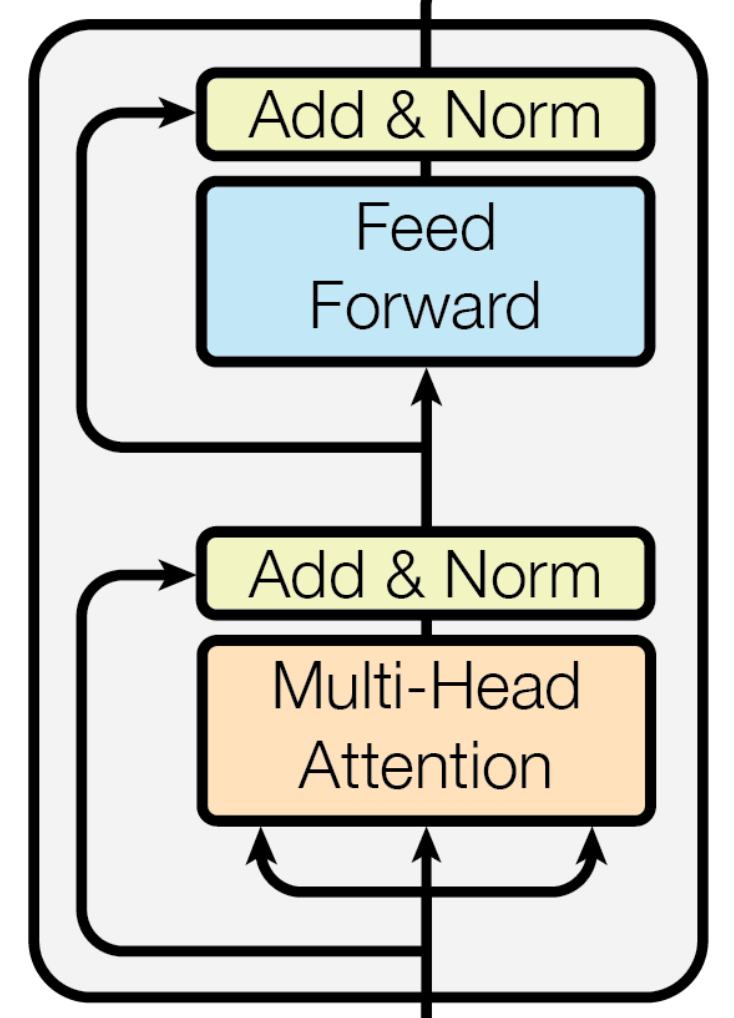
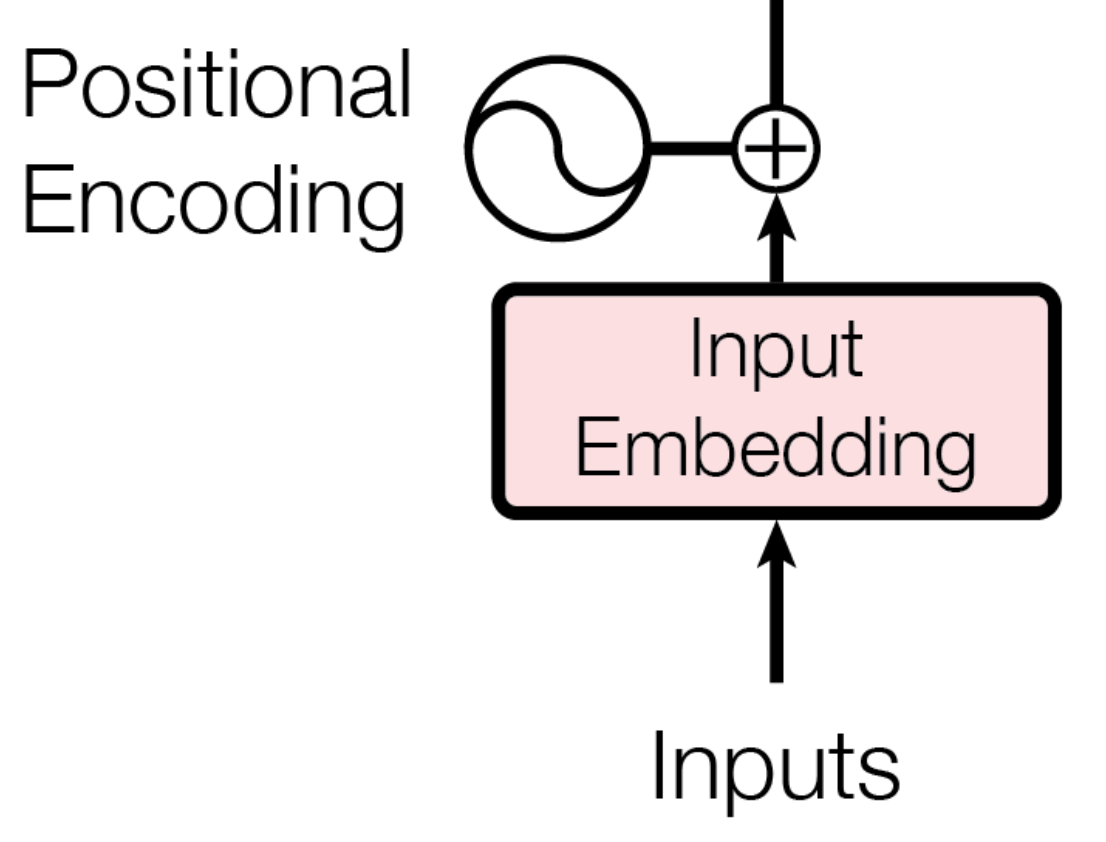
class Encoder(nn.Module):
def __init__(self, N, hidden_dim, num_head, inner_dim, max_length=100):
super().__init__()
self.N = N # N : 인코딩에서 사용할 블록 수
self.hidden_dim = hidden_dim # hidden_dim : 임베딩 차원 수
self.num_head = num_head # num_head : 멀티-헤드 어텐션의 헤드 수
self.inner_dim = inner_dim # inner_dim : Feed forward layer 안에서 잠깐 수행되는 dim
self.embedding = nn.Embedding(num_embeddings=VOCAB_SIZE, embedding_dim=hidden_dim, padding_idx=0)
self.pos_embedding = nn.Embedding(max_length, hidden_dim)
self.enc_layers = nn.ModuleList([EncoderLayer(hidden_dim, num_head, inner_dim) for _ in range(N)])
self.dropout = nn.Dropout(p=0.1)
def forward(self, input):
batch_size = input.shape[0]
seq_len = input.shape[1]
mask = makeMask(input, option='padding')
pos = torch.arange(0, seq_len).unsqueeze(0).repeat(batch_size, 1).to(device)
# Input Embedding + Pos
output = self.dropout(self.embedding(input) + self.pos_embedding(pos))
# Dropout
output = self.dropout(output)
# N encoder layer
for layer in self.enc_layers:
output = layer(output, mask)
return output
input값에 대해 embedding, pos_embedding 층을 쌓고, 인코더 층을 N회 쌓습니다.
makeMask(option=’padding’)은 padding mask를 의미합니다. 인코딩 층에 같이 input으로 넣는 걸 확인하실 수 있습니다. pos_embedding이나 padding mask가 기억이 안나신다면 이론 쪽 게시물을 다시 한번 읽어주세요.
Encoder Layer
class EncoderLayer(nn.Module):
def __init__(self, hidden_dim, num_head, inner_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.num_head = num_head
self.inner_dim = inner_dim
self.multiheadattention = Multiheadattention(hidden_dim, num_head)
self.ffn = FFN(hidden_dim, inner_dim)
self.layerNorm1 = nn.LayerNorm(hidden_dim)
self.layerNorm2 = nn.LayerNorm(hidden_dim)
self.dropout1 = nn.Dropout(p=0.1)
self.dropout2 = nn.Dropout(p=0.1)
def forward(self, input, mask = None):
output = self.multiheadattention(srcQ= input, srcK = input, srcV = input, mask = mask)
output = self.dropout1(output)
output = input + output
output = self.layerNorm1(output)
output_ = self.ffn(output)
output_ = self.dropout2(output_)
output = output + output_
output = self.layerNorm2(output)
return output
멀티헤드 어텐션 후 skip-connection, layernorm, FFN 모두 그림과 같이 구현을 했습니다.
이제 각각의 세부 모듈을 구현해보도록 하겠습니다.
Multi-Head Attention
class Multiheadattention(nn.Module):
def __init__(self, hidden_dim: int, num_head: int):
super().__init__()
# embedding_dim, d_model, 512 in paper
self.hidden_dim = hidden_dim
# 8 in paper
self.num_head = num_head
# head_dim, d_key, d_query, d_value, 64 in paper (= 512 / 8)
self.head_dim = hidden_dim // num_head
self.scale = torch.sqrt(torch.FloatTensor()).to(device)
self.fcQ = nn.Linear(hidden_dim, hidden_dim)
self.fcK = nn.Linear(hidden_dim, hidden_dim)
self.fcV = nn.Linear(hidden_dim, hidden_dim)
self.fcOut = nn.Linear(hidden_dim, hidden_dim)
self.dropout = nn.Dropout(0.1)
def forward(self, srcQ, srcK, srcV, mask=None):
##### SCALED DOT PRODUCT ATTENTION ######
Q = self.fcQ(srcQ)
K = self.fcK(srcK)
V = self.fcV(srcV)
Q = rearrange(
Q, 'bs seq_len (num_head head_dim) -> bs num_head seq_len head_dim', num_head=self.num_head)
K_T = rearrange(
K, 'bs seq_len (num_head head_dim) -> bs num_head head_dim seq_len', num_head=self.num_head)
V = rearrange(
V, 'bs seq_len (num_head head_dim) -> bs num_head seq_len head_dim', num_head=self.num_head)
attention_energy = torch.matmul(Q, K_T)
if mask is not None :
attention_energy = torch.masked_fill(attention_energy, (mask == 0), -1e+4)
attention_energy = torch.softmax(attention_energy, dim = -1)
result = torch.matmul(self.dropout(attention_energy),V)
##### END OF SCALED DOT PRODUCT ATTENTION ######
# CONCAT
result = rearrange(result, 'bs num_head seq_len head_dim -> bs seq_len (num_head head_dim)')
result = self.fcOut(result)
return result
우션 멀티헤드 어텐션에 맞춰 디멘젼을 구성하고, Q,K,V를 통해 어텐션을 계산한 후, padding mask에 따라 해당 위치를 음의 값으로 치환하여 softmax 이후 0이 되게끔 로직을 구현했습니다.
이렇게 나온 멀티헤드 어텐션에 최종적으로 Linear함수를 적용하여 학습을 하고 있습니다.
FFN
class FFN(nn.Module):
def __init__ (self, hidden_dim, inner_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.inner_dim = inner_dim
self.fc1 = nn.Linear(hidden_dim, inner_dim)
self.fc2 = nn.Linear(inner_dim, hidden_dim)
self.relu = nn.ReLU(inplace=False)
self.dropout = nn.Dropout(0.1)
def forward(self, input):
output = input
output = self.fc1(output)
output2 = self.relu(output)
output2 = self.dropout(output)
output3 = self.fc2(output2)
return output3
makeMask
def makeMask(tensor, option: str) -> torch.Tensor:
# PAD_IDX = 0
if option == 'padding':
tmp = torch.full_like(tensor, fill_value=PAD_IDX).to(device)
mask = (tensor != tmp).float()
mask = rearrange(mask, 'bs seq_len -> bs 1 1 seq_len ') # shape 변경
elif option == 'lookahead':
padding_mask = makeMask(tensor, 'padding')
padding_mask = repeat(
padding_mask, 'bs 1 1 k_len -> bs 1 new k_len', new=padding_mask.shape[3])
mask = torch.ones_like(padding_mask)
mask = torch.tril(mask)
mask = mask * padding_mask # query 1 기준 2 이후, 2기준 3 이후값에 대해 masking
return mask
masking 함수입니다. padding, lookahead 모두 구현된 것을 확인하실 수 있습니다. 인코더에서는 padding만 사용하며, 디코더의 첫 블록에서는 둘 다 사용해야 합니다.
padding의 경우 makemask의 input은 embedding하기 전 input 값이므로, masking을 통해 문장의 끝 이후 부분을 찾아낼 수 있습니다. ex) [나(1), 는(5), 밥(3), 을(11), 먹었(14), 다(7), 0, 0, 0, 0]
lookahead의 경우 padding된 mask를 input으로 한 후 torch.tril과 연산해 각 시점에서 볼 수 있는 정보를 제한합니다.
Decoder
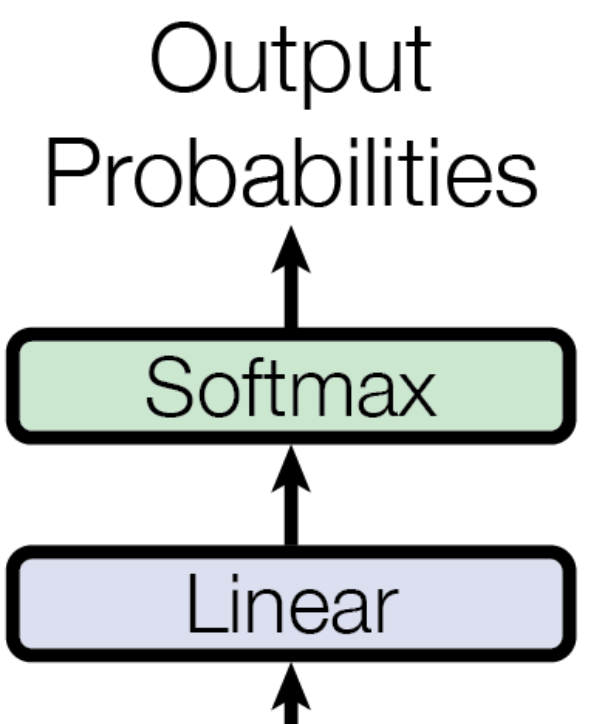
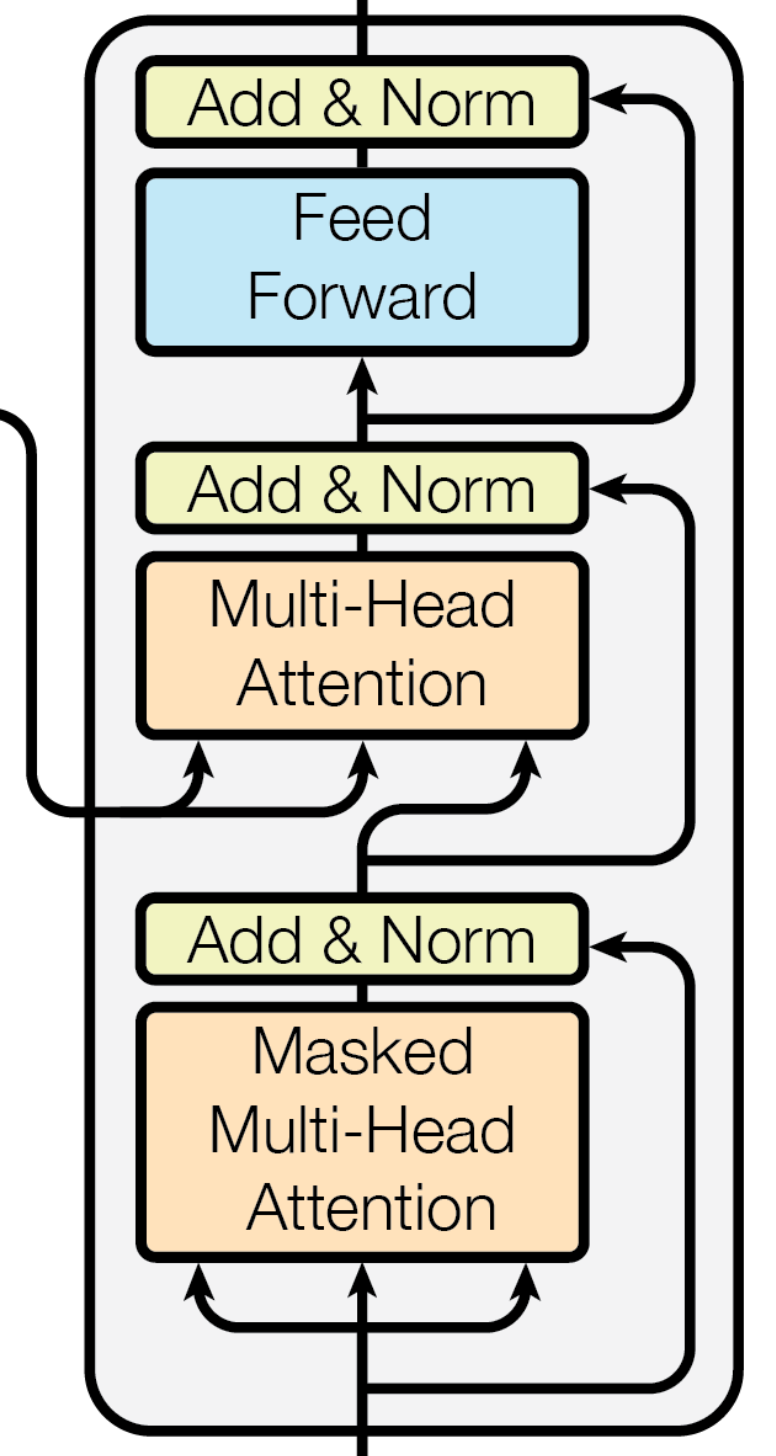
class Decoder(nn.Module):
def __init__ (self, N, hidden_dim, num_head, inner_dim, max_length=100):
super().__init__()
# N : number of encoder layer repeated
self.N = N
self.hidden_dim = hidden_dim
self.num_head = num_head
self.inner_dim = inner_dim
self.embedding = nn.Embedding(num_embeddings=VOCAB_SIZE, embedding_dim=hidden_dim, padding_idx=0)
self.pos_embedding = nn.Embedding(max_length, hidden_dim)
self.dec_layers = nn.ModuleList([DecoderLayer(hidden_dim, num_head, inner_dim) for _ in range(N)])
self.dropout = nn.Dropout(p=0.1)
self.finalFc = nn.Linear(hidden_dim, VOCAB_SIZE)
def forward(self, input, enc_src, enc_output):
lookaheadMask = makeMask(input, option= 'lookahead')
paddingMask = makeMask(enc_src, option = 'padding')
# embedding layer
output = self.embedding(input)
# Dropout
output = self.dropout(output)
for layer in self.dec_layers:
output = layer(output, enc_output, paddingMask, lookaheadMask)
logits = self.finalFc(output)
output = torch.softmax(logits, dim = -1)
output = torch.argmax(output, dim = -1)
return logits, output
첫 레이어의 input을 위해 두 masking을 모두 준비하는 걸 확인하실 수 있습니다.
DecoderLayer
class DecoderLayer(nn.Module):
def __init__(self, hidden_dim, num_head, inner_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.inner_dim = inner_dim
self.multiheadattention1 = Multiheadattention(hidden_dim, num_head)
self.layerNorm1 = nn.LayerNorm(hidden_dim)
self.multiheadattention2 = Multiheadattention(hidden_dim, num_head)
self.layerNorm2 = nn.LayerNorm(hidden_dim)
self.ffn = FFN(hidden_dim, inner_dim)
self.layerNorm3 = nn.LayerNorm(hidden_dim)
self.dropout1 = nn.Dropout(p=0.1)
self.dropout2 = nn.Dropout(p=0.1)
self.dropout3 = nn.Dropout(p=0.1)
def forward(self, input, enc_output, paddingMask, lookaheadMask):
# first multiheadattention
output = self.multiheadattention1(input, input, input, lookaheadMask)
output = self.dropout1(output)
output = output + input
output = self.layerNorm1(output)
# second multiheadattention
output_ = self.multiheadattention2(output, enc_output, enc_output, paddingMask)
output_ = self.dropout2(output_)
output = output_ + output
output = self.layerNorm2(output)
# Feedforward Network
output_ = self.ffn(output)
output_ = self.dropout3(output_)
output = output + output_
output = self.layerNorm3(output)
return output
첫 레이어에서는 lookahead mask가 들어가는 것과, input값들이 들어가는 Self Attention을 구현한 것을 체크할 수 있고, 그 뒤에서는 인코더의 output값이 들어가는 일반적인 Attention이 구현된 것과 padding mask값이 들어가는 걸 확인할 수 있습니다.
위의 코드들을 사용하여 최종적으로 모델을 로드할 수 있습니다.
if __name__ == '__main__':
N = 2
HIDDEN_DIM = 256
NUM_HEAD = 8
INNER_DIM = 512
PAD_IDX = 0
EOS_IDX = 3
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Transformer(N, HIDDEN_DIM, NUM_HEAD, INNER_DIM).to(device)
이전 페이지에서는 Transformer가 무엇인지 이론을 확인할 수 있었습니다. 이번 페이지에서는 Transformer를 구현해보도록 하겠습니다.
[논문 리뷰] Transformer 리뷰
자연어 처리 뿐만 아니라 최근 컴퓨터 비전 영역에서도 사용되고 있는 Attention이라는 기법을 적용한 유명한 모델인 Transformer를 알아보도록 하겠습니다. Transformer 트랜스포머는 2017년 구글에서 발
dyddl1993.tistory.com
Transformer
class Transformer(nn.Module):
def __init__(self, N = 2, hidden_dim = 256, num_head = 8, inner_dim = 512):
super().__init__()
self.encoder = Encoder(N, hidden_dim, num_head, inner_dim)
self.decoder = Decoder(N, hidden_dim, num_head, inner_dim)
def forward(self, enc_src, dec_src):
enc_output = self.encoder(enc_src)
logits, output = self.decoder(dec_src, enc_src, enc_output)
return logits, output
아키텍쳐 그림과 같이 decoder가 dec_src, enc_src, 그리고 enc_output을 받도록 설정합니다.
Encoder
class Encoder(nn.Module):
def __init__(self, N, hidden_dim, num_head, inner_dim, max_length=100):
super().__init__()
self.N = N # N : 인코딩에서 사용할 블록 수
self.hidden_dim = hidden_dim # hidden_dim : 임베딩 차원 수
self.num_head = num_head # num_head : 멀티-헤드 어텐션의 헤드 수
self.inner_dim = inner_dim # inner_dim : Feed forward layer 안에서 잠깐 수행되는 dim
self.embedding = nn.Embedding(num_embeddings=VOCAB_SIZE, embedding_dim=hidden_dim, padding_idx=0)
self.pos_embedding = nn.Embedding(max_length, hidden_dim)
self.enc_layers = nn.ModuleList([EncoderLayer(hidden_dim, num_head, inner_dim) for _ in range(N)])
self.dropout = nn.Dropout(p=0.1)
def forward(self, input):
batch_size = input.shape[0]
seq_len = input.shape[1]
mask = makeMask(input, option='padding')
pos = torch.arange(0, seq_len).unsqueeze(0).repeat(batch_size, 1).to(device)
# Input Embedding + Pos
output = self.dropout(self.embedding(input) + self.pos_embedding(pos))
# Dropout
output = self.dropout(output)
# N encoder layer
for layer in self.enc_layers:
output = layer(output, mask)
return output
input값에 대해 embedding, pos_embedding 층을 쌓고, 인코더 층을 N회 쌓습니다.
makeMask(option=’padding’)은 padding mask를 의미합니다. 인코딩 층에 같이 input으로 넣는 걸 확인하실 수 있습니다. pos_embedding이나 padding mask가 기억이 안나신다면 이론 쪽 게시물을 다시 한번 읽어주세요.
Encoder Layer
class EncoderLayer(nn.Module):
def __init__(self, hidden_dim, num_head, inner_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.num_head = num_head
self.inner_dim = inner_dim
self.multiheadattention = Multiheadattention(hidden_dim, num_head)
self.ffn = FFN(hidden_dim, inner_dim)
self.layerNorm1 = nn.LayerNorm(hidden_dim)
self.layerNorm2 = nn.LayerNorm(hidden_dim)
self.dropout1 = nn.Dropout(p=0.1)
self.dropout2 = nn.Dropout(p=0.1)
def forward(self, input, mask = None):
output = self.multiheadattention(srcQ= input, srcK = input, srcV = input, mask = mask)
output = self.dropout1(output)
output = input + output
output = self.layerNorm1(output)
output_ = self.ffn(output)
output_ = self.dropout2(output_)
output = output + output_
output = self.layerNorm2(output)
return output
멀티헤드 어텐션 후 skip-connection, layernorm, FFN 모두 그림과 같이 구현을 했습니다.
이제 각각의 세부 모듈을 구현해보도록 하겠습니다.
Multi-Head Attention
class Multiheadattention(nn.Module):
def __init__(self, hidden_dim: int, num_head: int):
super().__init__()
# embedding_dim, d_model, 512 in paper
self.hidden_dim = hidden_dim
# 8 in paper
self.num_head = num_head
# head_dim, d_key, d_query, d_value, 64 in paper (= 512 / 8)
self.head_dim = hidden_dim // num_head
self.scale = torch.sqrt(torch.FloatTensor()).to(device)
self.fcQ = nn.Linear(hidden_dim, hidden_dim)
self.fcK = nn.Linear(hidden_dim, hidden_dim)
self.fcV = nn.Linear(hidden_dim, hidden_dim)
self.fcOut = nn.Linear(hidden_dim, hidden_dim)
self.dropout = nn.Dropout(0.1)
def forward(self, srcQ, srcK, srcV, mask=None):
##### SCALED DOT PRODUCT ATTENTION ######
Q = self.fcQ(srcQ)
K = self.fcK(srcK)
V = self.fcV(srcV)
Q = rearrange(
Q, 'bs seq_len (num_head head_dim) -> bs num_head seq_len head_dim', num_head=self.num_head)
K_T = rearrange(
K, 'bs seq_len (num_head head_dim) -> bs num_head head_dim seq_len', num_head=self.num_head)
V = rearrange(
V, 'bs seq_len (num_head head_dim) -> bs num_head seq_len head_dim', num_head=self.num_head)
attention_energy = torch.matmul(Q, K_T)
if mask is not None :
attention_energy = torch.masked_fill(attention_energy, (mask == 0), -1e+4)
attention_energy = torch.softmax(attention_energy, dim = -1)
result = torch.matmul(self.dropout(attention_energy),V)
##### END OF SCALED DOT PRODUCT ATTENTION ######
# CONCAT
result = rearrange(result, 'bs num_head seq_len head_dim -> bs seq_len (num_head head_dim)')
result = self.fcOut(result)
return result
우션 멀티헤드 어텐션에 맞춰 디멘젼을 구성하고, Q,K,V를 통해 어텐션을 계산한 후, padding mask에 따라 해당 위치를 음의 값으로 치환하여 softmax 이후 0이 되게끔 로직을 구현했습니다.
이렇게 나온 멀티헤드 어텐션에 최종적으로 Linear함수를 적용하여 학습을 하고 있습니다.
FFN
class FFN(nn.Module):
def __init__ (self, hidden_dim, inner_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.inner_dim = inner_dim
self.fc1 = nn.Linear(hidden_dim, inner_dim)
self.fc2 = nn.Linear(inner_dim, hidden_dim)
self.relu = nn.ReLU(inplace=False)
self.dropout = nn.Dropout(0.1)
def forward(self, input):
output = input
output = self.fc1(output)
output2 = self.relu(output)
output2 = self.dropout(output)
output3 = self.fc2(output2)
return output3
makeMask
def makeMask(tensor, option: str) -> torch.Tensor:
# PAD_IDX = 0
if option == 'padding':
tmp = torch.full_like(tensor, fill_value=PAD_IDX).to(device)
mask = (tensor != tmp).float()
mask = rearrange(mask, 'bs seq_len -> bs 1 1 seq_len ') # shape 변경
elif option == 'lookahead':
padding_mask = makeMask(tensor, 'padding')
padding_mask = repeat(
padding_mask, 'bs 1 1 k_len -> bs 1 new k_len', new=padding_mask.shape[3])
mask = torch.ones_like(padding_mask)
mask = torch.tril(mask)
mask = mask * padding_mask # query 1 기준 2 이후, 2기준 3 이후값에 대해 masking
return mask
masking 함수입니다. padding, lookahead 모두 구현된 것을 확인하실 수 있습니다. 인코더에서는 padding만 사용하며, 디코더의 첫 블록에서는 둘 다 사용해야 합니다.
padding의 경우 makemask의 input은 embedding하기 전 input 값이므로, masking을 통해 문장의 끝 이후 부분을 찾아낼 수 있습니다. ex) [나(1), 는(5), 밥(3), 을(11), 먹었(14), 다(7), 0, 0, 0, 0]
lookahead의 경우 padding된 mask를 input으로 한 후 torch.tril과 연산해 각 시점에서 볼 수 있는 정보를 제한합니다.
Decoder
class Decoder(nn.Module):
def __init__ (self, N, hidden_dim, num_head, inner_dim, max_length=100):
super().__init__()
# N : number of encoder layer repeated
self.N = N
self.hidden_dim = hidden_dim
self.num_head = num_head
self.inner_dim = inner_dim
self.embedding = nn.Embedding(num_embeddings=VOCAB_SIZE, embedding_dim=hidden_dim, padding_idx=0)
self.pos_embedding = nn.Embedding(max_length, hidden_dim)
self.dec_layers = nn.ModuleList([DecoderLayer(hidden_dim, num_head, inner_dim) for _ in range(N)])
self.dropout = nn.Dropout(p=0.1)
self.finalFc = nn.Linear(hidden_dim, VOCAB_SIZE)
def forward(self, input, enc_src, enc_output):
lookaheadMask = makeMask(input, option= 'lookahead')
paddingMask = makeMask(enc_src, option = 'padding')
# embedding layer
output = self.embedding(input)
# Dropout
output = self.dropout(output)
for layer in self.dec_layers:
output = layer(output, enc_output, paddingMask, lookaheadMask)
logits = self.finalFc(output)
output = torch.softmax(logits, dim = -1)
output = torch.argmax(output, dim = -1)
return logits, output
첫 레이어의 input을 위해 두 masking을 모두 준비하는 걸 확인하실 수 있습니다.
DecoderLayer
class DecoderLayer(nn.Module):
def __init__(self, hidden_dim, num_head, inner_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.inner_dim = inner_dim
self.multiheadattention1 = Multiheadattention(hidden_dim, num_head)
self.layerNorm1 = nn.LayerNorm(hidden_dim)
self.multiheadattention2 = Multiheadattention(hidden_dim, num_head)
self.layerNorm2 = nn.LayerNorm(hidden_dim)
self.ffn = FFN(hidden_dim, inner_dim)
self.layerNorm3 = nn.LayerNorm(hidden_dim)
self.dropout1 = nn.Dropout(p=0.1)
self.dropout2 = nn.Dropout(p=0.1)
self.dropout3 = nn.Dropout(p=0.1)
def forward(self, input, enc_output, paddingMask, lookaheadMask):
# first multiheadattention
output = self.multiheadattention1(input, input, input, lookaheadMask)
output = self.dropout1(output)
output = output + input
output = self.layerNorm1(output)
# second multiheadattention
output_ = self.multiheadattention2(output, enc_output, enc_output, paddingMask)
output_ = self.dropout2(output_)
output = output_ + output
output = self.layerNorm2(output)
# Feedforward Network
output_ = self.ffn(output)
output_ = self.dropout3(output_)
output = output + output_
output = self.layerNorm3(output)
return output
첫 레이어에서는 lookahead mask가 들어가는 것과, input값들이 들어가는 Self Attention을 구현한 것을 체크할 수 있고, 그 뒤에서는 인코더의 output값이 들어가는 일반적인 Attention이 구현된 것과 padding mask값이 들어가는 걸 확인할 수 있습니다.
위의 코드들을 사용하여 최종적으로 모델을 로드할 수 있습니다.
if __name__ == '__main__':
N = 2
HIDDEN_DIM = 256
NUM_HEAD = 8
INNER_DIM = 512
PAD_IDX = 0
EOS_IDX = 3
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Transformer(N, HIDDEN_DIM, NUM_HEAD, INNER_DIM).to(device)