멀티 레이블 분류를 보기에 앞서 머신러닝 모델은 크게 회귀 모델과 분류 모델로 나뉠 수 있습니다. 여기서 분류 모델은 이 사진이 개인지 고양이인지를 분류하는 모델, 사람이 맞는지 틀린지를 분류하는 모델 등 0과 1로 라벨링해서 분류를 할 수 있는 이진 분류 문제와, 어떤 사진이 개인지 고양이인지 토끼인지 고라니인지 등 다수의 레이블 중 하나를 선택하는 멀티 클래스 분류가 존재합니다. 이 두 개의 분류 방법 이진 분류, 멀티 클래스 분류는 각각 다른 Activation function , Loss function을 사용합니다. 여기서는 Activation function을 간단하게 정리해보겠습니다. Loss function에 대해서는 쉽게 정리된 링크로 대체합니다. 링크 해당 링크에서는 뒤에 나올 내용인 ..
MTCNN MTCNN에 대해 간단하게 리뷰해보도록 하겠습니다. MTCNN은 최초 논문을 통해 공개된 저자의 버전이 존재하고, Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks 가공한 버전들이 존재합니다. 하단 링크는 그 중 가장 퍼블릭한 버전입니다. GitHub - ipazc/mtcnn: MTCNN face detection implementation for TensorFlow, as a PIP package. 파라미터 버전마다 약간의 차이는 존재할 수 있으나 기본적으로 조절할 수 있는 파라미터는 다음과 같습니다. weights_file, min_face_size, steps_threshold, scale..
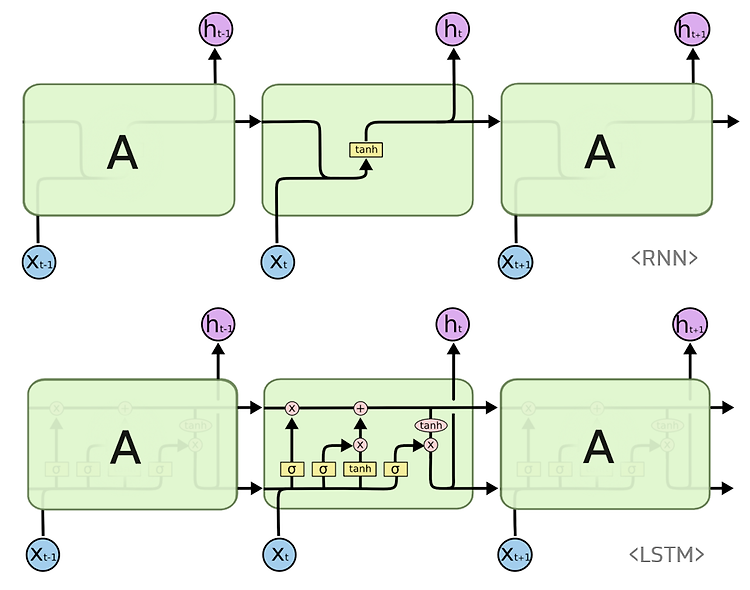
LSTM은 기존 RNN의 긴 기간의 의존성 문제에 약한 단점을 보완한 RNN의 한 기법입니다. 간단한 구조인 RNN과 달리 꽤 복잡한 구조로 이루어져 있습니다. 구조가 어려운 만큼 이해하기 어려워 rastgo’s blog의 게시물 RNN과 LSTM을 이해해보자! · ratsgo's blog 을 따라 적어보며 이해하고자 했습니다. 기본 구조 Cell State LSTM은 위의 그림의 직선처럼 Cell state라는 긴 통로가 존재합니다. 이 Cell state를 활용하여 이전 단계의 정보를 이어가게 됩니다. 이러한 Cell state에 정보를 더하거나 잊게 하는 방법이 존재하는데 이를 Gate를 통해 제어하게 됩니다. 그림의 Cell state 상의 X,+ 두 기호가 각 게이트를 말하며 각각 Forget ..
현재 진행중인 프로젝트를 하는 데 있어 Head pose estimating 관련 논문인 FSA-Net 을 알아본 김에 향후 까먹지 않도록 블로그에 리뷰해놓고자 합니다. 데모 파일에 대해 주석처리한 내용도 있어 하단에 링크로 남겼습니다. 글을 작성하는 이유가 제가 까먹지 않기 위한 목적이라 글이 깔끔하지 않을 수 있습니다. 모델 소개 우선 FSA-Net에서 어떠한 결과값이 나오는 지 확인해 보겠습니다. 단일 이미지를 Input으로 받았을 때 FSA-Net은 세 가지의 값을 Output합니다. 각각의 값이 Yaw, Pitch, Roll을 의미합니다. Yaw Pitch Roll 정의 Yaw Pitch Roll 정의 원문 : http://blog.naver.com/blueintel/130001901193 Im..
XAI(설명가능한 AI)에서는 다양한 방법들이 존재하지만, 그 중 특히 CNN의 필터와 관련된 방법론들이 많이 존재합니다. 이를 공부하기 전에 CNN의 이론들에 대해 알아보고자 합니다. CNN은 시각 피질에 대한 연구에 이미지를 DNN으로 처리하는 데 생기는 문제점을 해결하기 위해 점진적으로 진화한 알고리즘입니다. 이미지 분야에 DNN이 사용되지 않는 이유는 어마어마하게 많은 파라미터가 생긴다는 단점과, 이미지와는 다르게 위치 정보를 이용할 수 없다는 단점들이 존재하기 때문입니다. 이 페이지에서는 CNN의 중요한 두 가지 구조인 합성곱층, 풀링층에 대해 우선 설명하고, 나머지 연결부분들에 대해 간단히 요약해서 최종적으로는 기본적인 하나의 CNN 모델의 구조에 대해 설명해보고자 합니다. 합성곱층(Convo..
공분산과 상관계수에 대해 정리해보고자 한다. 코베리언스, 코릴레이션이라고 말하는 사람들도 종종 보인다. 이상한 단어가 아니라 그냥 공분산, 상관계수니 그렇게 들으면 된다. 공분산(Covariance) 공분산은 두 개의 변수들 간의 편차를 활용한 변수이다. Cov(X,Y) = E((X-Mean(X))(Y-Mean(Y))) 로 표현된다. 이를 활용해 두 변수의 상관관계의 부호를 파악할 수 있다. 하지만 각 변수마다 단위 등에 의해 크기가 차이날 수 있는데, 이런 문제로 인해 상관관계의 크기를 알기는 힘들다. 참고로 위의 식을 전개하면 Cov(X,Y) = E(XY) - mean(X)mean(Y)가 된다. 여기서 X,Y가 독립이면 E(XY) = E(X)E(Y)가 되므로 공분산이 0이 된다. 상관계수(Correl..
고유값(eigen value)와 고유벡터(eigen vector) 0이 아닌 어떤 열벡터 v가 있다고 생각해보자. v를 기준으로, 어떤 A라는 정방행렬과의 연산을 취하면 원래와는 다른 벡터 b가 나오게 된다. Av = b 하지만 어떤 특정한 행렬은 기존 벡터와 평행하지만 크기만 다른 벡터가 나오게 된다. Av = Λv 이 상황은 정방행렬과 어떤 벡터와의 연산은 그 벡터에 대해 상수배를 취한 것과 같다로 정리할 수 있다. 여기서 상수 Λ를 고유값(eigen value), 벡터 v를 고유벡터(eigen vector)라고 한다. 거듭제곱의 단순화처럼, 행렬 A에 대해 고유값, 고유벡터를 찾음으로써 문제 해결의 복잡도를 단순화 시킬 수 있다는 장점이 있다. 주성분분석에서의 활용 주성분분석 관점에서 고유값과 고유..
경사하강법(Gradient descent) 함수의 기울기를 구해 최소값에 이를 때까지 반복시키는 방법. 학습률만큼 계속 이동하며 학습하기 때문에 적절한 학습률을 지정해야 한다. 딥러닝에서는 비용함수를 사용하여 이 값을 최소화하는 방식을 사용한다. 수식을 통해 기울기가 0인 지점을 찾을 수도 있겠지만 실제 함수가 어떠한 형태인지 모르는 문제(비선형함수 등 문제)등으로 인해 컴퓨터로 gradient descent를 구현하여 사용한다. 학습률의 경우 너무 높을 경우 수렴하기가 힘드며, 너무 낮을 경우 local minima 문제에 빠질 수 있다. local minima 문제를 해결하기 위해 모멘텀을 주로 사용한다. 비용 함수(Cost function) 예측 값과 실제 결과 간의 차이를 비용(Cost)라 하며,..
활성화 함수를 사용하는 이유 선형 시스템은 아무리 쌓더라도 망을 깊어지게 할 수는 없다. 예를 들어 a,b라는 상수 x,y라는 변수에 대해 f(ax+by) = af(x) + bf(y)라는 성질으로 인해 깊은(deep) 망을 구현할 수 없다는 단점을 가지고 있다. 이런 단점을 해결하기 위해 활성화 함수를 사용한다. 결론적으로 활성화함수는 non-linearity한 시스템을 만들어준다. non-linearity(비선형성)의 중요성 데이터가 복잡해지고, feature들의 차원이 증가하면서 데이터의 분포가 선형적이지 않고 비선형적으로 나타나는데, 예를 들어 이진 분류 문제에서 직선으로 두 분포를 나눌 수 있으면 좋겠지만 선형 boundary로 표현하지 못할 가능성이 더 높다. 이런 문제를 non-linearit..
이상치(Outlier) 아웃라이어란 데이터 상의 다른 값들의 분포와 비교했을때 비정상적으로 떨어져있는 관측치를 말한다. 이상치 찾는 간단한 방법 1. 사분위수 2. 정규분포 3. 도메인(이건 간단한건 아님) 4. 시각화 시각화를 이용한 방법 boxplot, scatterplot을 사용해 시각화를 하고, 나온 그림 상 이상한 부분을 눈으로 찾는 방법을 말한다. 보통 시각화단계에서 나타난 이상치들은 정규분포, 사분위수 관련 공식으로도 찾아지기는 한다. # boxplot(단변수), sactterplot(이변수) 정규분포를 이용한 방법 mean +- 3std 정규분포 공식을 이용한 것으로 양 끝쪽 부분인 2.5%, 97.5% 외를 이상치로 판별하는 방법을 말한다. 사분위수를 이용한 방법 3Q or 1Q +- 1..