
DCGAN(Deep Convolutional GAN)은 GAN의 대표적인 모델로써, GAN에 컨볼루전망을 적용하여 성능을 향상시킨 모델입니다. 간단하게 DCGAN에 대해 설명한 후 실습과 함께 상세하게 알아보도록 하겠습니다.
DCGAN 요약
DCGAN은 2016년에 발표된 모델로 GAN의 가장 대표적인 모델입니다.
https://arxiv.org/abs/1511.06434
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
In recent years, supervised learning with convolutional networks (CNNs) has seen huge adoption in computer vision applications. Comparatively, unsupervised learning with CNNs has received less attention. In this work we hope to help bridge the gap between
arxiv.org
벡터 간 연산
DCGAN은 마치 word2vec과 같이 각각의 이미지를 생성하는 Generator의 입력으로 들어가는 noise vector(z)간의 연산이 가능하다는 장점을 가지고 있습니다. 정확하게 이 z를 잠재 공간(latent space)라고 하며, 각각의 결과에 input으로 들어간 z를 더하거나 뺄 수가 있습니다.
물론 바로 더하거나 빼는 것은 아니고, 같은 z들의 평균(보통 3개) 등을 구한 후 그 값을 더하거나 빼야 어느 정도 성능이 나온다고 합니다.
예를 들어 안경 쓴 남자를 만들어내는 다수의 z를 평균낸 후, 안경을 쓰지 않은 남자(역시 평균)를 빼고, 안경을 쓰지 않은 여자(평균)를 더한다면 안경을 쓴 여자의 이미지가 생성되는 노이즈 벡터가 됩니다.

이렇게 연산이 가능하기 때문에 왼쪽을 보고 있는 사람과 오른쪽을 보고 있는 사람의 벡터의 평균을 계산하고, 그 사이를 보간한 후 제너레이터에 넣으면 정 중앙을 바라보는 얼굴이 만들어지는 등의 활용이 가능합니다.
그리고, 이 잠재 공간 z값을 조금씩 변화시키면 Generator의 결과 이미지가 부드러운 변화를 보여주게 됩니다.

Convolution
이름에서도 알 수 있듯이 DCGAN은 컨볼루전망을 GAN에 적용한 논문입니다. Loss가 기존 GAN과 같음에도 불구하고 이러한 구조를 적용한 덕에 기존 GAN 대비 더 안정적인 학습이 가능하다고 합니다.
추가로 Convolution Layer에서 사용하는 filter를 dropout하면 그 filter가 맡고 있던 영역을 제거할 수 있다고 합니다. 예를 들어 창문이 있는 침실 등의 이미지를 만드는 모델이 있다면, 창문과 관련된 filter를 dropout한 순간 해당 모델은 창문이 없는 침실을 생성하게 됩니다.

Loss
DCGAN은 기존 GAN과 동일한 Loss를 사용합니다. 어떻게 이 Loss를 구현해서 사용하는지는 실습에서 자세히 다루겠습니다.
DCGAN 실습
파이토치 튜토리얼을 따라 실습해보도록 하겠습니다.
https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html
DCGAN Tutorial — PyTorch Tutorials 1.11.0+cu102 documentation
Note Click here to download the full example code DCGAN Tutorial Author: Nathan Inkawhich Introduction ———— This tutorial will give an introduction to DCGANs through an example. We will train a generative adversarial network (GAN) to generate new c
pytorch.org
Discriminator(판별자)는 Strided Convolution Layer, Batch Norm Layer, LeakyReLU 로 구현되어 있습니다. input은 3x64x64 이며, output은 해당 input이 real data인지에 대한 확률값입니다.
Generator(생성자)는 Convolutional-Transpose Layer, Batch Norm Layer, ReLU로 구현되어 있습니다. input은 noise 벡터, output은 3x64x64 이미지입니다.
Import
DCGAN 구현에 필요한 라이브러리를 임포트합니다.
from __future__ import print_function
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
# Random Seed를 고정합니다.
manualSeed = 999 # manualSeed = random.randint(1, 10000) # use if you want new results
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
Parameter
모델의 input 등에 필요한 파라미터를 정의합니다.
# Load Data
dataroot = "data/celeba" # Dataset의 경로입니다.
workers = 2 # DataLoader로 데이터를 로드하기 위한 쓰레드 갯수입니다.
# Batch size during training
batch_size = 128 # 논문에서 사용한 128의 배치 사이즈입니다.
# Image size, Channel
image_size = 64 # 이미지 사이즈를 의미합니다.
nc = 3 # RGB 3채널을 의미합니다.
# Noise Vector
nz = 100 # 노이즈 벡터의 길이를 의미합니다. 튜토리얼에서는 100을 지정했습니다.
# Size of feature maps in generator
ngf = 64 # 제너레이터에서 만들어지는 피쳐 맵의 크기입니다.
# Size of feature maps in discriminator
ndf = 64 # 판별자에서 만들어지는 피쳐 맵의 크기입니다.
# Number of training epochs
num_epochs = 5 # 에포크 수를 정의합니다. 튜토리얼에서는 속도 문제로 5를 정의했습니다.
# Learning rate for optimizers
lr = 0.0002 # 러닝 레이트를 설정합니다.
# Beta1 hyperparam for Adam optimizers
beta1 = 0.5 # Adam 옵티마이저에서 사용할 하이퍼파라미터 Beta1의 값입니다. 고정해야 한다고 합니다.
# Number of GPUs available. Use 0 for CPU mode.
ngpu = 1
Data Load & Preprocessing
DCGAN 파이토치 튜토리얼에서 사용하는 데이터셋은 Celeb-A입니다. 다운로드는 Celeb-A Faces dataset 또는 Google Drive에서 받을 수 있습니다. 그 중 사용할 데이터세트는 img_align_celeba.zip입니다. 데이터를 다운로드하면 celeba 폴더를 생성해서 해당 폴더에서 압축을 해제하시면 됩니다.
/path/to/celeba
-> img_align_celeba
-> 188242.jpg
-> 173822.jpg
-> 284702.jpg
...이제 간단하게 데이터세트에 대해 전처리를 한 후, 데이터 로더를 만들고 배치해보겠습니다.
# 데이터세트를 생성합니다.
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size), # resize 전처리
transforms.CenterCrop(image_size), # 가운데를 자르는 전처리
transforms.ToTensor(), # pytorch tensor로 타입 변경
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 노말라이즈 처리
]))
# 데이터로더를 생성합니다.
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
# CPU, GPU 등 디바이스를 설정합니다.
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
# 시각화
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))
Weight Initialization
DCGAN 논문에서 저자는 모든 모델 가중치가 mean 0, std 0.02인 정규 분포에서 무작위로 초기화되어야 한다고 지정합니다. 하기 weights_init함수는 초기화된 모델을 입력으로 사용하고 이 기준을 충족하기 위해 모든 컨볼루션, 컨볼루션-전치 및 배치 정규화 계층을 다시 초기화합니다. 이 기능은 초기화 직후 모델에 적용됩니다.
# custom weights initialization called on netG and netD
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
Generator
제너레이터(G)는 노이즈 벡터(z)를 input으로 받아 RGB 이미지를 생성하는 모델입니다. DCGAN에서의 output 이미지 shape는 3x64x64 입니다.
모델은 nn.ConvTranspose2d를 통해 구현되며, 각각의 레이어는 nn.BatchNorm2d, nn.ReLU함수와 함께 구현하고 있습니다. output값은 nn.Tanh()를 통해 출력되며 [-1, 1] 범위를 리턴합니다.
추가로 튜토리얼에서는 nn.BatchNorm2d함수의 배치 및 존재가 트레이닝 중 가중치의 흐름을 도와주는 중요한 레이어라고 설명하고 있습니다.
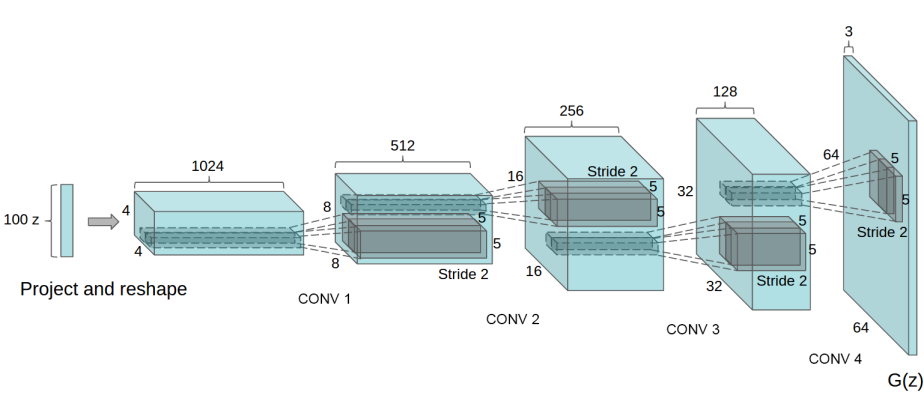
Generator의 코드는 다음과 같습니다.
# Generator Code
# nz = 100 / ngf = 64, nc = 3
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)Generator를 생성한 후 가중치를 초기화합니다.
# Create the generator
netG = Generator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.02.
netG.apply(weights_init)
# Print the model
print(netG)# Create the generator
netG = Generator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.02.
netG.apply(weights_init)
# Print the model
print(netG)노이즈 벡터에서부터 여러 겹의 nn.ConvTranspose2d망을 쌓은 후 최종적으로 3x64x64 의 이미지를 생성하는 걸 확인할 수 있습니다.
추가로 저는 어떻게 Generator가 state shape를 키워나가는지 nn.ConvTranspose2d의 동작이 많이 헷갈려서 코드를 이해하는 데 시간이 좀 걸렸습니다. 저처럼 헷갈리시는 분들을 위해 nn.ConvTranspose2d의 동작에 대해서는 간단하게 추가로 정리해보겠습니다.
컨볼루젼트렌스포즈2디멘젼정리예정
Discriminator
판별자(D)는 이미지가 real data인지 fake data인지를 판별하는 이진 분류기라고 할 수 있습니다. 그렇기 때문에 input값은 3x64x64 RGB 이미지입니다.
모델은 nn.Conv2d, nn.BatchNorm2d, nn.LeakyReLU를 통해 구현하며 마지막에 nn.sigmoid 함수를 통해 최종 확률값을 출력합니다.
논문에서는 Discriminator는 더 많은 레이어로 확장해도 되지만 stride nn.Conv2d, nn.BatchNorm2d, nn.LeakyReLU를 사용하는 것이 중요하다고 합니다. 또한 pooling 대신 stride conv2d를 사용하는 이유는 이렇게 구현할 경우 자체적으로 풀링 기능을 학습할 수 있기 때문이라고 설명하고 있습니다. 또한 Generator와 마찬가지로 nn.BatchNorm2d과 nn.LeakyReLU 함수를 사용함으로써 G와 D에 healthy한 가중치 흐름을 만들 수 있다고 합니다.
Discriminator의 코드는 다음과 같습니다.
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)Discriminator 역시 생성 후 가중치를 초기화합니다.
# Create the Discriminator
netD = Discriminator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netD.apply(weights_init)
# Print the model
print(netD)Discriminator(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(12): Sigmoid()
)
)nn.Conv2d 을 통해 shape이 변경되는 점이 헷갈리실 경우 CNN 또는, 위의 nn.ConvTranspose2d 설명을 보시면 좋을 것 같습니다.
Loss Functions and Optimizers
지금까지 데이터를 준비하고 생성자와 판별자를 구현한 후 가중치를 초기화했습니다. 이제는 훈련을 위한 Loss Function과 Optimizer를 정의할 차례입니다.
파이토치 튜토리얼에서는 Binary Cross Entropy Loss (BCELoss)를 사용했습니다. BCELoss — PyTorch 1.11.0 documentation
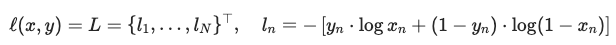
BCELoss를 사용하는 이유는, y 입력을 실제 데이터인지의 레이블로 지정할 경우 1 또는 0이 곱해지며 각각의 목적 함수에 맞는 계산식을 만들 수 있기 때문입니다. 조금 더 설명해보도록 하겠습니다.
Discriminator Loss
Discriminator의 Loss는 하단의 수식과 같습니다.
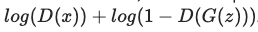
이제 위의 BCELoss로 Discriminator Loss를 계산해보겠습니다. 우선 real data일 경우 yn = 1이 되어 앞의 수식은 1이 곱해져 그대로 남고 뒤의 수식은 0이 곱해지므로 사라지게 됩니다. 여기서의 xn은 D(x)이므로 하단의 수식이 나오게 됩니다.
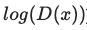
fake data일 경우에는 yn = 0이 되어 위와는 다르게 뒤의 수식이 남게 됩니다. 여기서의 xn은 제너레이터가 생성한 D(G(z))이므로 하단의 수식이 나오게 됩니다.
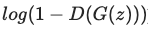
이제 이렇게 구한 두 Loss를 더하면 Discriminator Loss가 됩니다. 훈련에서는 이 값을 최대화하는 방향으로 가중치를 업데이트할 것입니다.
Generator Loss
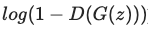
Generator는 약간 다르게 작동합니다. 위의 수식을 최소화하는 방향으로 Loss를 설정해야 하는데, 이는 아래의 수식을 최대화하는 것과 내용이 같습니다.
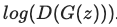
이 식을 BCELoss로 구현하려면, real data의 label인 yn = 1로 넣어야 합니다. 여기서의 xn은 제너레이터가 생성한 D(G(z))이므로 위의 수식을 만들 수 있습니다.
Code
밑의 코드는 위의 Loss를 구현하고, real data의 레이블을 1, fake data의 레이블을 0으로 지정한 후 마지막으로 각각의 모델에 대한 Adam Optimizer를 설정하는 코드입니다. 논문에서 설정한 하이퍼파라미터는 다음과 같습니다. lr = 0.0002, Beta1 = 0.5
Generator의 학습 진행을 추적하기 위해 가우스 분포에서 가져온 고정된 noise batch를 생성하는 구문도 추가했습니다. 훈련 루프에서 주기적으로 이 fixed_noise를 Generator에 넣음으로써 noise에서 나오는 이미지를 확인할 수 있습니다.
# Initialize BCELoss function
criterion = nn.BCELoss()
# Create batch of latent vectors that we will use to visualize
# the progression of the generator
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
# Establish convention for real and fake labels during training
real_label = 1.
fake_label = 0.
# Setup Adam optimizers for both G and D
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))Training
파이토치에서는 하이퍼파라미터를 잘못 설정할 경우 왜 잘못되었는지도 모르게 모드 붕괴(mode collapse)가 일어나기 때문에 GAN을 훈련하는 것은 일종의 예술과도 같다고 설명합니다.
이 예제에서는 Ian Goodfellow의 논문 알고리즘 1을 따르면서 ganhacks에 표시된 모범 사례를 준수하며 훈련을 진행하겠습니다. 즉 fake, real data에 대해 다른 미니배치를 구성하고, G의 목적 함수 log D(G(z))를 최대화할 것입니다.
Part 1. Train The Discriminator
Discriminator은 input 이미지가 real, fake인지를 분류할 확률을 최대화하도록 훈련해야 합니다. 실질적으로 최대하해야 하는 값은 다음과 같습니다.
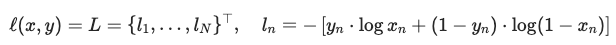
ganhacks의 별도 미니 배치 방법을 따라 Discriminator를 두 단계로 계산하겠습니다. 먼저 real data을 feed forward합니다. 이후 이에 따른 loss을 계산하고, gradients를 계산합니다.
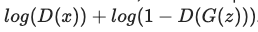
두번째로는 Generator로 fake data batch를 구성하고, 이를 feed forward하고 다시 loss를 계산하고, gradients를 누적합니다.
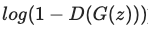
이렇게 누적된 gradients를 사용해 Discriminator의 Optimizer를 호출해 훈련할 수 있습니다.
Part 2. Train The Generator
이번에는 Generator를 학습해보도록 하겠습니다. Generator는 Discriminator가 fake data를 real data로 잘못 예측하게끔 만들어야 합니다. 이를 수식으로 정의하면, 다음의 Loss를 최소화해야합니다.
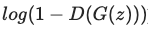
이를 조금 수정하면, 다음의 Loss를 최대화해야 하는 것으로도 볼 수 있습니다.
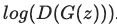
이제 우리는 Loss를 정의했으므로 앞의 Part 1. 에서의 Generator output을 Discriminator로 분류했던 상황으로 돌아가 실제 레이블을 사용해서 Generator의 손실을 계산할 수 있습니다. 이렇게 얻은 Loss로 gradients을 계산하고 optimizer step에서 Generator의 parameters를 업데이트하는 과정을 거칩니다.
Report
각각의 에포크가 끝날 때 fixed_noise batch Generator를 통해 푸시하여 Generator의 훈련 진행 상황을 시각적으로 추적하는 코드도 구현해보았습니다. 해당 리포트를 통해 나오는 값들은 다음과 같습니다.
- Loss_D - Discriminator의 Loss
log(D(x))+log(1−D(G(z)))) - Loss_G - Generator의 Loss
log(D(G(z))) - D(x) - 모든 Real data batch에 대한 Discriminator의 평균 output을 말합니다. 1에 가깝게 시작해야 하고 이론적으로 Generator가 좋아질수록 판별이 어려워지므로 0.5에 수렴합니다.
- D(G(z)) - 모든 Fake data batch에 대한 Discriminator의 평균 output을 말합니다. 0에 가깝게 시작되야 하고, 이 역시 이론적으로 0.5에 수렴하게 됩니다.
# 리스트 설정
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
# For each epoch
for epoch in range(num_epochs):
# For each batch in the dataloader
for i, data in enumerate(dataloader, 0):
############################
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
###########################
## Real Data에 대한 Discriminator 훈련입니다.
netD.zero_grad()
# Format batch
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, dtype=torch.float, device=device)
# Forward pass real batch through D
output = netD(real_cpu).view(-1)
# Calculate loss on all-real batch
errD_real = criterion(output, label)
# Calculate gradients for D in backward pass
errD_real.backward()
D_x = output.mean().item()
## Fake Data에 대한 Discriminator 훈련입니다.
# 제너레이터에 넣을 노이즈를 생성합니다.
noise = torch.randn(b_size, nz, 1, 1, device=device)
# 제너레이터로 Fake Data를 생성하고 이를 명시합니다.
fake = netG(noise)
label.fill_(fake_label)
# Classify all fake batch with D
output = netD(fake.detach()).view(-1)
# Calculate D's loss on the all-fake batch
errD_fake = criterion(output, label)
# Calculate the gradients for this batch, accumulated (summed) with previous gradients
errD_fake.backward()
D_G_z1 = output.mean().item()
# Compute error of D as sum over the fake and the real batches
errD = errD_real + errD_fake
# Update D
optimizerD.step()
############################
# (2) Update G network: maximize log(D(G(z)))
###########################
## Generator 훈련입니다
netG.zero_grad()
label.fill_(real_label) # Generator에는 real_label을 넣습니다.(G는 fake를 real로 만들고자 함)
# Since we just updated D, perform another forward pass of all-fake batch through D
output = netD(fake).view(-1)
# Calculate G's loss based on this output
errG = criterion(output, label)
# Calculate gradients for G
errG.backward()
D_G_z2 = output.mean().item()
# Update G
"""
파이토치는 이렇게 옵티마이저 step으로 역전파를 하는데
이렇게 하면 Discriminator의 gradient는 freeze된 것과 같습니다.
"""
optimizerG.step()
# Output training stats
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# Save Losses for plotting later
G_losses.append(errG.item())
D_losses.append(errD.item())
# Check how the generator is doing by saving G's output on fixed_noise
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1Result
이제 훈련의 결과를 살펴보겠습니다. 먼저 훈련 중 D와 G의 손실이 어떻게 변했는지 살펴보겠습니다. 둘째, 모든 epoch에 대해 fixed_noise 배치에서 G의 출력을 시각화합니다. 그리고 세 번째로 G의 가짜 데이터 배치 옆에 실제 데이터 배치를 살펴보겠습니다.
Loss versus training iteration
아래는 D, G의 손실을 시각화 한 그래프입니다.
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()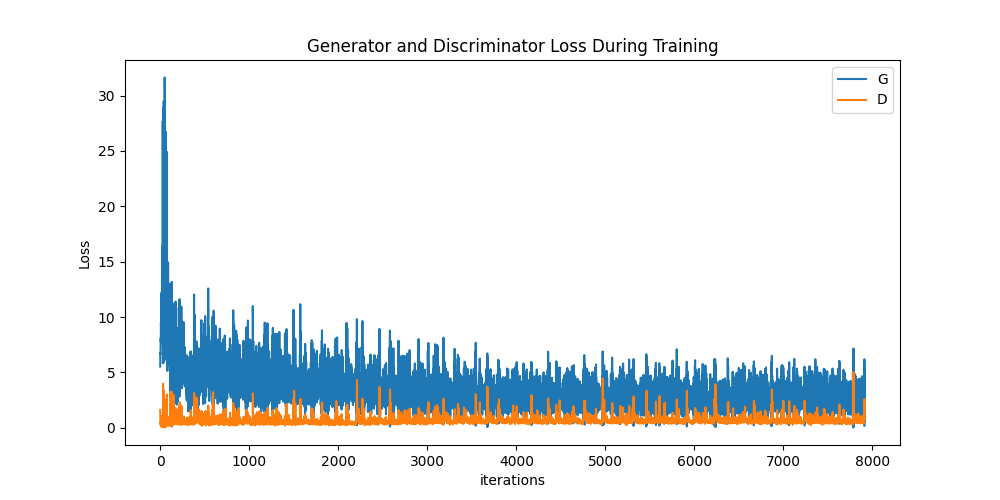
Visualization of G’s progression
우리는 매 epoch 후에 fixed_noise 배치에 Generator의 출력을 저장했었습니다. 하단의 구문은 그 출력을 시각화하는 코드입니다. 애니메이션 시각화라 튜토리얼 사이트나 직접 구현해서 확인하셔야 합니다.
#%%capture
fig = plt.figure(figsize=(8,8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())Real & Fake Image
마지막으로 실제 이미지와 가짜 이미지를 나란히 살펴보며 마무리 하겠습니다.

참고 및 사용 예제
DCGAN Tutorial — PyTorch Tutorials 1.11.0+cu102 documentation
GitHub - nashory/gans-awesome-applications: Curated list of awesome GAN applications and demo