
이미지 분야에 Transformer 구조를 적용한 아키텍쳐를 제시한 논문인 ViT에 대해 정리하고자 합니다.
ViT는 구글에서 발표한 논문으로, 기존에 자연어 처리 분야에서 널리 사용되고 있는 트랜스포머를 비전 분야에 적용함으로써 SOTA의 성능을 보인 논문입니다. 이 모델 자체는 엄청나게 많은 양의 데이터로 Pre-train 해야 한다는 단점은 있지만, 어쨋든 높은 성능을 보인다는 점과, 비전 분야에 트랜스포머를 성공적으로 적용한 논문이라는 의의가 있습니다.
Architecture
ViT는 다음과 같은 구조로 이루어져 있습니다.
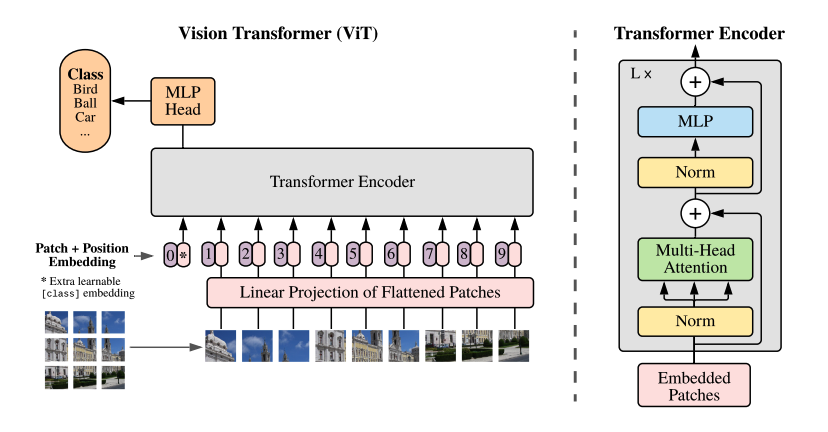
이 아키텍쳐를 기준으로 어떻게 동작하는지를 설명해보도록 하겠습니다.
Patch, Embedding
ViT는 이미지가 들어왔을 때, 먼저 여러개의 Patch로 자르는 작업을 실행합니다. 기본적으로 하나의 Patch는 16x16의 사이즈를 가지고 있으므로 이 값을 기준으로 설명한다면 하나의 패치는 16x16x3의 크기를 가지게 됩니다. 이렇게 나온 3차원 Patch를 1차원으로 Flatten한 후, Linear Projection을 통해 $D$개의 길이로 다시 변경해주는 작업을 합니다.
이렇게 나온 각각의 패치에 대해 Position Embedding을 더해줍니다. 여기서 Position Embedding은 각 패치의 순서를 알려주는 역할이라고 볼 수 있습니다. 다만 Position Embedding을 더하기 전 패치들의 맨 앞에 Class token을 추가하는 작업이 있습니다.
아래 이미지의 붉은 박스 부분을 보며 설명해보도록 하겠습니다. 이미지를 9개의 패치로 나눈 후, Linear Projection을 수행합니다. 이후에 패치들의 맨 앞에 Class token(* 부분) 을 붙인 후 Class token부터 순서대로 0-9를 Position Embedding하는 것을 볼 수 있습니다.
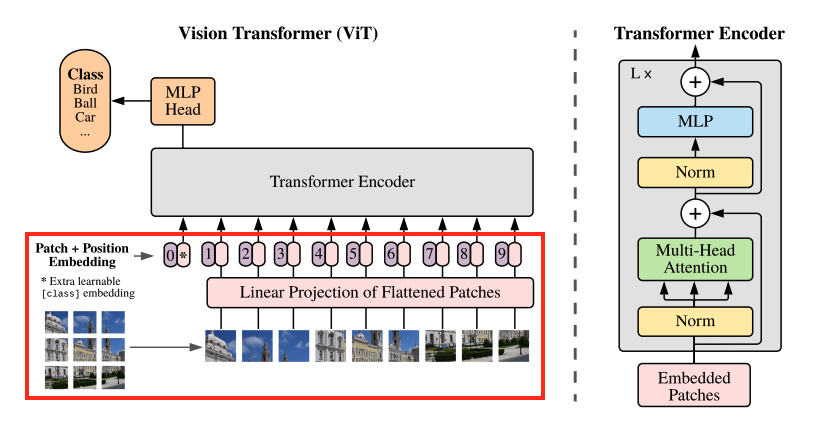
다만 논문의 저자는 코드에서 Patch Embedding 시에 Patch + Flatten + Linear Projection 를 사용하지 않고 패치 크기의 커널, 스트라이드를 적용한 Conv2D 레이어를 사용하고 있습니다. 이러한 방식이 일반적인 방식보다 성능이 좋았다고 합니다.
# Embedding
class Embedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224):
self.patch_size = patch_size
super().__init__()
# patch embedding
# linear 모델 대신 conv layer를 사용하여 성능 향상
self.projection = nn.Sequential(nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e h w -> b (h w) e'),)
# add CLS token
self.cls_token = nn.Parameter(torch.randn(1, 1, emb_size))
# positional embedding
'''
왜 0~1사이 값을 쓰는가?
왜 concat으로 붙이는것이 아니라 더할까?
<https://www.blossominkyung.com/deeplearning/transfomer-positional-encoding#4d058603-db0f-4d62-bb49-d85ea6dcbfc6>
'''
self.positions = nn.Parameter(torch.randn((img_size // patch_size) ** 2 + 1, emb_size))
def forward(self, x: Tensor):
b, _, _, _ = x.shape
x = self.projection(x) # patch embedding
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b) # add CLS
x = torch.cat([cls_tokens, x], dim=1)
x += self.positions # add positional embedding
return x
구현한 Embedding 클래스를 보면서 설명해보도록 하겠습니다. 논문에서 표현한 Flatten + Linear이 아닌 Conv2D를 사용해 Patch를 진행한 것을 확인할 수 있고, 패치의 맨 앞 부분에 CLS 토큰을 추가한 부분도 확인할 수 있습니다.
Positional Encoding의 경우 0,1 사이의 랜덤한 값을 생성한 후, 임베딩 된 패치에 더해주는 것을 확인할 수 있습니다. 저는 이 값을 붙이는 것이 아니라 왜 더하는 것인지 이해가 안돼서 좀 힘들었는데 이에 대해서 자세히 정리해 준 블로그 덕에 이해할 수 있었습니다. 해당 블로그는 하기 링크에서 확인하실 수 있습니다.
트랜스포머 transformer positional encoding
트랜스포머 Transformer Attention is All You Need Postional Encoding
www.blossominkyung.com
이렇게 Positional Encoding까지 완료되면 Transformer Encoder 부분에 들어갈 준비는 마무리됩니다.
Transformer Encoder
이렇게 임베딩 된 인풋값은 Transformer 블록에서 연산을 수행하게 됩니다. ViT의 Transformer는 인코더만 사용하며 아래 빨간색 박스 부분입니다.

일반적인 트랜스포머 인코더 부분이라고 볼 수 있습니다.
Multi-Head Attention
우선 멀티헤드 어텐션 부분을 구현해보도록 하겠습니다.
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 512, num_heads: int = 8, dropout: float = 0):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
self.keys = nn.Linear(emb_size, emb_size)
self.queries = nn.Linear(emb_size, emb_size)
self.values = nn.Linear(emb_size, emb_size)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x : Tensor, mask: Tensor = None) -> Tensor:
# split keys, queries and values in num_heads
queries = rearrange(self.queries(x), "b n (h d) -> b h n d", h=self.num_heads)
keys = rearrange(self.keys(x), "b n (h d) -> b h n d", h=self.num_heads)
values = rearrange(self.values(x), "b n (h d) -> b h n d", h=self.num_heads)
# sum up over the last axis
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1/2)
att = F.softmax(energy, dim=-1) / scaling
att = self.att_drop(att)
# sum up over the third axis
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
Query, Key, Value를 Multi-Head에 맞춰 정렬해준 후,
queries = rearrange(self.queries(x), "b n (h d) -> b h n d", h=self.num_heads)
keys = rearrange(self.keys(x), "b n (h d) -> b h n d", h=self.num_heads)
values = rearrange(self.values(x), "b n (h d) -> b h n d", h=self.num_heads)
쿼리와 키의 곱연산을 수행하고,
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys)
소프트맥스, 스케일링을 적용한 후
scaling = self.emb_size ** (1/2)
att = F.softmax(energy, dim=-1) / scaling
att = self.att_drop(att)
벨류와의 곱연산을 수행합니다. 아래 공식을 구현했다고 볼 수 있습니다.(멀티헤드 부분이 추가된)
$$ Attention(Q,K,V) = softmax({QK^T\over{\sqrt{d_K}}})V $$
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
마지막으로 멀티헤드 가중치 연산을 수행하게끔 설정하면 멀티헤드 어텐션 클래스 구현이 완료됩니다.
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
Residual Connection
Residual Connection 부분은 간단하게 구현할 수 있습니다.
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return x
MLP
멀티헤드 어텐션 이후에는 간단한 MLP 연산이 있습니다.
'''
nn.Sequential을 받으면 forward를 안해도 된다고 합니다.
'''
class FeedForwardBlock(nn.Sequential):
def __init__(self, emb_size: int, expansion: int = 4, drop_p: float = 0.):
super().__init__(
nn.Linear(emb_size, expansion * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(expansion * emb_size, emb_size),
)
Encoder
각각의 모듈들을 활용해 인코더 블록을 구현하면 다음과 같습니다.
# Encoder
class TransformerEncoderBlock(nn.Module):
def __init__(self,
emb_size: int = 768,
drop_p: float = 0.,
forward_expansion: int = 4,
forward_drop_p: float = 0.,
**kwargs):
super().__init__()
self.residual_1 = ResidualAdd(nn.Sequential(nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, **kwargs),
nn.Dropout(drop_p)))
self.residual_2 = ResidualAdd(nn.Sequential(nn.LayerNorm(emb_size),
FeedForwardBlock(emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)))
def forward(self, x: Tensor):
residual_1 = self.residual_1(x)
residual_2 = self.residual_2(residual_1)
return residual_2
이 인코더 블록들을 L개 쌓으면 최종 인코더가 준비됩니다.
class TransformerEncoder(nn.Sequential):
def __init__(self, depth: int = 12, **kwargs):
super().__init__(*[TransformerEncoderBlock(**kwargs) for _ in range(depth)])
MLP
마지막으로 MLP를 거쳐 최종 Class를 예측합니다. 이 부분 역시 일반적인 리니어 연산이라고 볼 수 있습니다.
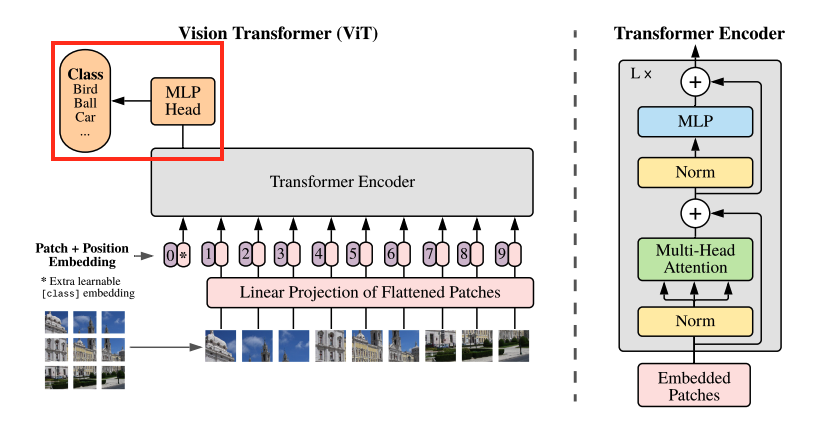
간단하게 다음과 같이 구현할 수 있습니다.
# ClassificationHead
class ClassificationHead(nn.Sequential):
def __init__(self, emb_size: int = 768, n_classes: int = 1000):
super().__init__()
self.classblock = nn.Sequential(Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))
def forward(self, x: Tensor) -> Tensor:
rtn = self.classblock(x)
return rtn
ViT
지금까지 구현한 모든 모듈을 종합하여 ViT를 구현하면 다음과 같습니다.
# ViT
class ViT(nn.Module):
def __init__(self,
in_channels: int = 3,
patch_size: int = 16,
emb_size: int = 768,
img_size: int = 224,
depth: int = 12,
n_classes: int = 1000,
**kwargs):
super().__init__()
self.vit = nn.Sequential(Embedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes),)
def forward(self, x: Tensor) -> Tensor:
return self.vit(x)
최종 모델을 체크해보면 다음과 같습니다.
summary(ViT(), (3, 224, 224), device='cpu')
================================================================
Total params: 86,415,592
Trainable params: 86,415,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 379.35
Params size (MB): 329.65
Estimated Total Size (MB): 709.57
----------------------------------------------------------------
파라미터 갯수는 다른 구현된 ViT 모델들의 갯수와 동일한 것을 확인할 수 있었습니다.
참고
ViT 구현은 다음 게시물을 참고하여 작성했습니다. 정말 자세하게 정리되어 있습니다.
Implementing VisualTtransformer in PyTorch
Hi guys, happy new year! Today we are going to implement the famous Vi(sual) T(transformer) proposed in AN IMAGE IS WORTH 16X16 WORDS…
towardsdatascience.com
Positional Encoding에 대해서 되게 자세하게 설명해주신 게시물입니다.
트랜스포머 transformer positional encoding
트랜스포머 Transformer Attention is All You Need Postional Encoding
www.blossominkyung.com
ViT의 각 모듈들에 대해 세세하게 설명해주신 게시물입니다.
[논문리뷰] Vision Transformer(ViT)
논문에 대해 자세하게 다루는 글이 많기 때문에 앞으로 논문 리뷰는 모델 구현코드 위주로 작성하려고 한다. AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE Alexey Dosovitskiy∗,† , Lucas Be
visionhong.tistory.com