
이번에는 논문 전체 리뷰가 아닌 특정 부분에 대한 간단한 리뷰를 진행하겠습니다.
제 생각을 적은 것이 많아서 잘못된 생각이 있을 수 있습니다. 이런 부분에 대해 댓글 남겨주시면 감사하겟습니다.
23년 4월에 나온 논문입니다. Stable Video Diffusion을 보려고 했는데 이 논문의 아키텍쳐를 사용했다고 해서 빠르게 짚어보려고 합니다.
소개
올해 2월, OpenAI에서 Sora라는 비디오 생성 모델을 공개했습니다. 입력으로 텍스트만 주어졌을 뿐인데 1분 분량의 사실적인 고화질 영상을 생성할 수 있는 아주 놀라운 기술입니다.

그 전에는 Pika Labs라는 스타트업에서 동영상 생성과 관련하여 기술을 선보인 적이 있었습니다.

관련 스타트업에서 공개한 기술도 있고, OpenAI에서도 발표한 모델이 있다면 Stable Diffusion에서도 분명 비슷한 시도가 있지 않을까 생각해 볼 수 있는데요. 바로 작년 11월에 Stable Video Diffusion이라는 논문이 발표되었습니다.
https://www.youtube.com/watch?v=G7mihAy691g
공식 페이지에서는 아까 소개한 Pika Labs나 다른 제품인 runway보다 사용자 선호도에서 높은 비율로 선택됬다는 결과를 확인할 수 있을 정도로 좋은 성능을 보이고 있습니다.

저는 이 Stable Video Diffusion 논문을 살펴보고 있었는데요. Stable Video Diffusion 논문에서 Video LDM 논문의 아키텍쳐를 그대로 사용했다는 내용을 보게 되어 우선적으로 이 논문을 정리하게 되었습니다. 그럼 주요 기능만 간단하게 리뷰해보도록 하겠습니다.
3. Latent Video Diffusion Models
3.1. Turning Latent Image into Video Generators
기존 Latent Diffusion Model(LDM)의 파라미터를 $\theta$라고 표현하고 LDM과 이미지를 처리하는 모든 레이어를 spatial layers $l^i_{\theta}$라고 표현하겠습니다. 여기서 $i$는 $i$번째 인덱스를 의미합니다.
이 기존 LDM은 개별 프레임에 대한 고품질 이미지 생성은 가능하지만 시간적인 인식은 없기 때문에 비디오 생성에는 맞지 않습니다. 그래서 저자는 시간적인 레이어를 추가하였는데요. 이 temporal layers는 $l^i_{\phi}$라고 표현하며 $l^i_{\theta}$이후에 적용됩니다.
이러한 $L$개의 additional temporal layers를 ${l^i_{\phi}}^L_{i=1}$이라고 표현하고 video-aware temporal backbone이라고 정의하겠습니다.
그리고 spatial layers, temporal layers를 모두 포함한 full model은 $f_{\theta,\phi}$라고 정의하고 전반적인 아키텍쳐는 아래 그림과 같습니다.

모델 아키텍쳐에 대해 설명을 시작해보면, 먼저 프레임 단위로 인코딩 된 인풋 비디오를 $\mathcal{E}(x)= \mathbf{z} \in \mathbb{R}^{T \times C \times H \times W}$라고 정의해보겠습니다. 여기서 $C$는 spatial latent channel이고, $H,W$는 spatial latent의 demension입니다.
이 인풋 값은 먼저 spatial layer에 적용됩니다. 배치 차원을 고려했을 때 시간 차원까지 배치로 처리하는 방법을 통해 shape를 (B * T) C H W 로 주어 적용한다고 볼 수 있습니다.
이후 temporal layer에 적용하기 위하여 shape를 변경하여 진행하는데요. 아래와 같이 진행하게 됩니다.

즉 temporal layer에서는 (B T) 차원에서 독립적인 처리가 아닌 T 차원에서의 처리를 통해 시간적인 정보를 사용했다고 이해할 수 있습니다. $l^i_{\phi}(z', c)$에서 사용한 c는 선택적인 조건부 텍스트 프롬프트를 의미합니다.
temporal layer 까지 적용한 최종 output인 $z'$는 그대로 사용하지 않고, 이전 LDM의 아웃풋 정보인 $z$ 정보와 가중치를 적용하여 더하게 되며 공식은 다음과 같습니다. 여기서 $\alpha^i_{\phi}$는 learnable parameter입니다.
$$
\alpha^i_{\phi} \mathbf{z} + (1-\alpha^i_{\phi})\mathbf{z}'; \alpha^i_{\phi} \in [0,1]
$$
저자는 두개의 다른 temporal mixing layer를 구현했는데 하나는 3D Convolution 기반의 residual block이며, 나머지 하나는 temporal attention block입니다. 아키텍쳐 그림은 다음과 같습니다.

추가로 시간에 대한 위치 인코딩은 sinusoidal embeddings을 사용했다고 합니다. 어떤 방법인지는 아직 살펴보지 못했고 나중에 논문을 정리해보도록 하겠습니다.
모델의 목적 함수는 다음과 같이 정의할 수 있습니다.

여기서 $\mathbf{z_\tau}$는 인코딩된 latent vector이며, 모델 중 spatial layer는 수정만 하고 가중치는 freeze하고 temporal layer $l^i_{\phi}$만 학습에 사용하여 최적화합니다.
모델의 스케줄러는 사용한 LDM의 스케줄러와 동일하게 설정하여 사용합니다.
참고로 $\alpha^i_{\phi} = 1$로 하면 temporal layer가 스킵되므로 기본 이미지가 출력되게 됩니다.
이러한 학습 방법은 spatial layer의 학습은 방대한 양의 이미지를 통해 학습을 진행하면 되고, 부족한 비디오 데이터로 temporal layer를 집중적으로 학습할 수 있다는 장점을 가지고 있습니다.
3.1.1 Temporal Autoencoder Finetuning
기존 스테이블 디퓨전을 그대로 사용하다보니 오토인코더 부분에서 시간적으로 일관된 이미지 시퀀스를 처리할 때 깜박임 아티팩트가 발생하는 문제가 있는데요. 이 문제를 해결하기 위해 오토인코더의 디코더 부분에 추가적인 temporal layers를 적용하였고, 비디오 데이터로 3D 컨볼루전으로 구성된 (patch-wise) temporal discriminator를 파인튜닝하여 문제를 해결했다고 합니다.
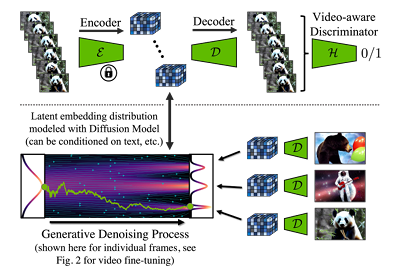
인코더는 LDM에 영향을 미치기 때문에 freeze하였다고 합니다.
3.2 Prediction Models for Long-Term Generation
지금까지 본 방법은 짧은 시퀀스의 비디오를 생성하는데 효과적이었지만, 긴 비디오를 생성할 때에는 한계가 있었는데요. 저자는 (첫 번째) S 개의 컨텍스트 프레임을 입력으로 주고 모델을 훈련하는 방법을 진행해보았습니다.
먼저 모델이 예측해야 하는 T - S 프레임에 대한 시간적인 이진 마스크인 $m_S$ 를 도입하였고, 이 마스크와 마스킹된 encoded video frame을 모델의 조건으로 넣습니다.
구체적으로 프레임은 LDM의 이미지 인코더를 통해 인코딩되어 마스크와 곱해지고, 학습된 다운샘플링 동작으로 처리된 후 temporal layers $l^i_{\phi}$에 적용됩니다. 아래 이미지와 같다고 볼 수 있습니다.
temporal layers에 적용될 때 마스크와 채널 부분에서 concatenate를 진행한 후 적용하는 것으로 보입니다.

이 이미지에서 $c_S = (m_S \circ z, m_S)$는 concatenated spatial conditioning으로, 마스크와 마스킹 된 encoded image를 병합한 것이라고 할 수 있습니다. 이 값은 optional한 conditioning입니다
그러므로 이 방법까지 적용한 목적 함수는 다음과 같이 변경됩니다. 아래 공식에서 $p_S$는 마스크 샘플링 분포를 의미합니다.

저자는 컨텍스트 프레임에 대해 0, 1 또는 2를 조건으로 주는 모델을 학습하여 0, 1 또는 2 컨텍스트 프레임을 조건으로 하는 예측 모델을 학습하여 classifier-free guidance 도 허용할 수 있게 만들었다고 합니다.
긴 길이의 동영상을 추론하는 동안, 샘플링 프로세스를 반복적으로 적용하여 최근에 예측된 새로운 컨텍스트를 재사용하였습니다. 첫 번째로 기본 이미지 모델에서 단일 컨텍스트 프레임을 만들어 놓고 이를 기반으로 초기 시퀀스를 구성한 후, 그 후 움직임을 인코딩하기 위해 두 컨텍스트 프레임을 조건으로 넣어 비디오를 생성하는 작업을 수행했습니다.
이 프로세스를 안정화하기 위해 classifier-free guidance가 유용하였다고 합니다. 샘플링하는 동안 모델의 가 이드는 다음과 같습니다. 여기서 s ≥ 1은 guidance scale입니다.

3.3 Temporal Interpolation for High Frame Rates
고해상도 비디오는 높은 화질 뿐만 아니라 높은 프레임률도 필요한데요. 이를 달성하기 위해 비디오에 대한 합성 과정을 두 부분으로 나누는 연구를 진행했습니다.
첫 번째는 3.1, 3.2절에서 설명한 프로세스로 상대적으로 낮은 프레임 속도로만 키 프레임을 생성할 수 있습니다. 두 번째로는 주어진 키 프레임 사이를 보간하는 작업을 수행하는 추가적인 모델입니다.
이 두번째 모델을 구현하기 위해서는 3.2에서 도입된 masking-conditioning mechanism을 사용해야 하는데요. 3.2절과는 다르게 예측이 아닌 프레임들 사이에 있는 보간하고자 하는 프레임을 마스킹하였습니다. 실험에서는 2개의 키 프레임 사이의 3개 프레임을 예측하는 T → 4T 보간 모델, 4T → 16T 보간 모델 등을 훈련하였습니다.

저는 위의 모델과 차이가 이 그림과 같다고 이해했습니다.
3.4 Temporal Fine-tuning of SR Models
이번에는 Super Resolution에 대해 확인해보도록 하겠습니다. 저자는 cascaded DMs 에서 영감을 얻어 Video LDM을 4x 까지 확장하였는데요. pixel-space DM을 통한 512×1024 확장, LDM upsampler를 통한 1280×2048 확장에 대한 연구를 진행했습니다. SR을 위해 noise level conditioning 방법들을 사용하여 노이즈 증강을 수행했습니다. 목적함수는 아래와 같습니다.
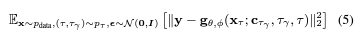
여기서 $c_{\tau_\gamma} = \alpha_{\tau_\gamma} \mathbf{x} + \sigma_{\tau_\gamma} \epsilon, \epsilon \sim \mathcal{N}(0,I)$인 concatenate된 noisy low-resolution image로 정의할 수 있고, $\tau_\gamma$는 노이즈 스케쥴 $\alpha_\tau, \sigma_\tau$로부터 low-resolution image에 더해지는 노이즈량입니다.
비디오 프레임을 독립적으로 업샘플링한다면 시간적인 정보가 떨어질 수 있기 때문에 이 SR 모델도 3.1절과 유사하게 파인튜닝하였고, 패치에 대해서 효율적으로 학습한 모델을 VideoLDM에 적용하였습니다.
아래 전체 프로세스 그림과 같이 저자는 LDM + 패치에 대해 학습한 Upsampler DM 의 조합이 가장 효과가 좋았다고 설명하고 있습니다.
pixel-space upsampler DM은 LDM과 동일한 백본을 사용했습니다.
3. 비디오 생성 프로세스 요약
그럼 지금까지 논문에 나온 비디오 생성 프로세스를 정리해보도록 하겠습니다.

- 먼저 Key Frame을 생성하는 Key Frame LDM을 통해 동영상의 전체적인 핵심 프레임들을 생성합니다.
- 이후 만들어진 프레임을 이용하여 보간을 수행합니다. 이 보간을 통해 비디오 내의 FPS를 늘리는 작업을 수행합니다. 이 과정에서 사용하는 Interpolation LDM은 Key Frame LDM과 이미지 백본의 파라미터를 공유합니다.
- 보간을 완료한 latent vector에 대해 디코딩을 수행합니다.
- Upsampler DM을 사용하여 Super Resolution을 수행하여 마무리합니다.
이러한 파이프라인을 통해 긴 길이, 높은 FPS를 가진 고화질의 동영상을 생성할 수 있었다고 합니다.
4. Experiments
본 논문의 비디오 생성 목표는 driving scene video generation과 text-to-video이며 다음과 같은 데이터세트를 사용했습니다.
(1) 사내의 실제 주행 장면 비디오 데이터셋으로, 512 x 1024(H x W)의 해상도를 가지고 있으며 각각 8초씩 683,060개의 비디오로 구성되어 있습니다. FPS는 최대 30입니다. 또한 비디오에는 주/야간 레이블 및 장면 내의 자동차 수에 대한 주석, 바운딩 박스에 대한 주석도 있습니다.
(2) WebVid-10M 데이터셋도 사용했습니다. 이 데이터셋은 52K 시간을 가진 10.7M 크기의 비디오-캡션 쌍으로 구성됩니다. 비디오 크기는 320 x 512로 전처리하여 사용했습니다.
모델 평가지표는 프레임별로 적용한 FID(Frechet Inception Distance)와 FVD(Frechet Video Distance)를 사용했다고 합니다. 다만 이 지표가 신뢰할 수 없기 때문에 human evaluation 추가로 수행하였다고 합니다. text-to-video의 경우 CLIP similarity (CLIPSIM)과 (video) inception score (IS)도 평가에 사용하였습니다.
IS는 모델이 얼마나 다양한 결과물을 만들 수 있는지, 그리고 만든 결과물을 분류 모델에 넣었을 때 분류 모델이 얼마나 정확하게 인식할 수 있는지를 평가하는 지표입니다.
FID는 Inception을 사용하여 원본 이미지와 생성한 이미지의 latent vecter 내의 거리를 비교하는 방법으로, FVD도 비슷한 지표일 것으로 판단됩니다. 다만 FID, FVD 만으로는 부족하기 때문에 사람의 평가를 함께 사용한 것으로 보이네요.
모델의 스케줄러는 DDIM을 사용했고 이러한 추가 아키텍처, 학습, 평가, 샘플링 및 데이터 세트 세부 정보는 Appendix에서 상세히 확인할 수 있습니다.
4.1 High-Resolution Driving Video Synthesis
RDS 데이터에 대해 4x SR까지 포함한 전체 Video LDM 파이프라인 훈련 결과에 대해 확인해보도록 하겠습니다. 먼저 주/야간 레이블과 혼잡도 등을 조절하여 훈련 중에 이런 레이블들을 무작위로 떨어트려 classifer-free guidance와 unconditional한 합성을 허용하였습니다.
저자는 위에서 소개한대로 비디오 프레임에서 이미지 백본 LDM을 훈련한 다음, 비디오에서 temporal layer를 훈련하는 방법을 사용했습니다.
완전히 다른 이미지 데이터셋에 대해 backbone LDM을 훈련한 다음 비디오에 시간층을 훈련한다고 생각했는데, 비디오를 이미지로 잘라서 이에 대해서 백본을 학습하는 방법이었네요.
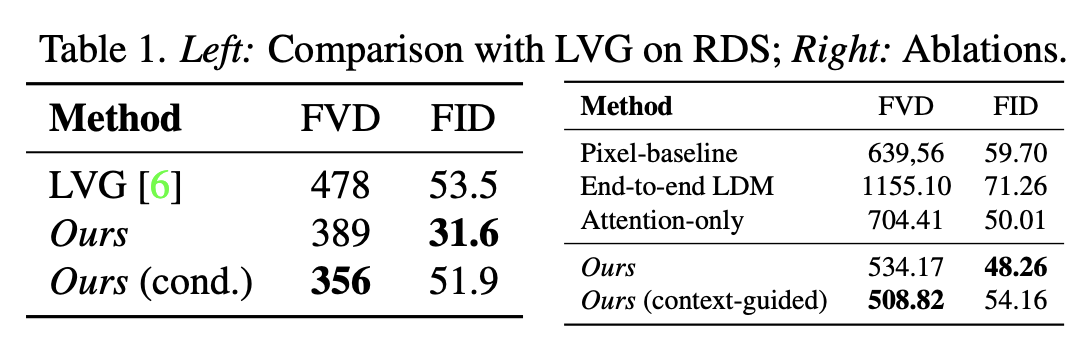
위의 표의 왼쪽 부분은 128x256 해상도로 이미지를 생성한 결과를 이전 SOTA인 LVG(Long Video GAN)과 비교한 결과인데요. LVG보다 더 좋은 성능을 보여주는 걸 확인할 수 있습니다. 특히 조건을 추가했을 때 FVD에서 성능이 더 향상하는 걸 확인할 수 있었습니다.

두번째 표는 사람의 선호도 평가인데요 LVG보다 더 좋은 선호도를 보이는 걸 확인할 수 있습니다.

다음으로 128 x 256 해상도의 30FPS 데이터를 사용하여 일반적인 이미지 업샘플러와 비디오 업샘플러간의 비교를 수행했습니다. FID는 각각의 이미지에 대한 비교이기 때문에 두 샘플러 간의 차이가 없지만 시간적인 정보가 주어질 경우 일반적인 이미지 업샘플러는 성능이 크게 저하되는 것을 확인할 수 있었습니다.
또한 prediction approach 방법을 사용할 경우 매우 길고 시간적으로도 일관된 고해상도 비디오를 생성할 수 있었다고 합니다.
여기서 말하는 prediction approach는 저자가 소개한 전체 파이프라인을 의미하는 것 같습니다.
4.1.1 Ablation Studies
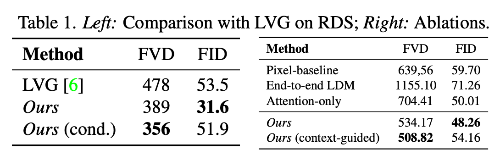
표 1의 오른쪽의 결과를 정리해보도록 하겠습니다.
먼저 Video LDM과 동일한 아키텍쳐를 사용하여 temporal fine-tuning 까지 수행한 Pixel-baseline을 평가하고, 기존 LDM에 대해 사전 훈련 없이 한번에 비디오에 모두를 학습하는 end-to-end 모델을 학습하여 평가합니다. 마지막으로 저자가 소개한 temporal layer는 컨볼루전 망과 어텐션망으로 구성되어 있는데, 어텐션만 사용해보는 방법을 연구하였습니다.
이러한 방법들보다 저자가 구현한 전체 파이프라인이 더 효율적인 것을 확인할 수 있으며 특히 context-guided를 주었을 경우 FVD의 상승을 확인할 수 있었습니다.
또한 저자는 디코더의 미세 조정 효과도 확인하였는데요.

표 3의 오른쪽을 보면 FID는 차이가 없지만 FVD에서 큰 차이를 보이는 걸 확인할 수 있습니다.
4.1.2 Driving Scenario Simulation

이번에는 Wild Dataset에서 훈련한 모델을 확인해보겠습니다. 초기 몇 개 프레임이 주어지면 VideoLDM은 그럴듯한 이후 상황을 생성하는 것을 확인할 수 있습니다.
또한 이미지 합성 태스크에 대해 별도의 바운딩 박스를 조건으로 넣는 VideoLDM도 훈련하였는데요. 다양한 자동차의 바운딩 박스를 통해 초기 이미지를 생성한 후, 이를 기반으로 비디오를 생성할 수 있었습니다.
4.2. Text-to-Video with Stable Diffusion
이번엔 Text-to-Video 작업에 대해 확인해보도록 하겠습니다. WebVid-10M 텍스트-캡션 비디오 데이터 세트(320 × 512)를 사용하여 소개한 훈련방법대로 훈련을 수행하고, 텍스트 조건도 추가합니다.
또한 공개적으로 사용 가능한 LDM 업샘플러를 비디오로 파인튜닝하여 4x 업스케일링을 하여 1280 x 2048 크기의 비디오를 생성할 수 있게 설정하였습니다.
저자는 113개 프레임으로 구성된 비디오를 생성하게끔 만들었고, 이는 24FPS의 4.7초 길이 영상이나 30FPS의 3.8초 길이의 영상으로 랜더링할 수 있습니다.
모델의 훈련 결과는 아래 사진과 같으며 비디오 데이터세트가 훨씬 작음에도 불구하고 다양한 비디오를 생성할 수 있었습니다.


저자는 제로샷 텍스트-비디오 생성을 평가하였는데요. UCF101, MSR-VTT에서 평가한 결과 Make-A-Video를 제외한 모든 방법보다 좋은 성능을 보였습니다.

저자는 Make-A-Video는 HD-VILA-100M 등의 더 많은 데이터를 사용하였고 text-to-video만을 목표로 하는 모델이기 때문에 다양한 작업을 할 수 있고 WebVid-10M만 학습한 VideoLDM과 차이가 있다는 점을 들어 방어하고 있습니다.
4.2.1 Personalized Text-to-Video with Dreambooth
비디오 LDM에는 별도의 공간 및 시간 계층이 있기 때문에 하나의 이미지 LDM 백본에서 훈련된 시간 계층이 다른 모델 체크포인트(예: 미세 조정)로 전송되는지 여부에 대한 질문이 발생합니다. 저희는 개인화된 텍스트-비디오 생성을 위해 이를 테스트합니다. 드림부쓰[66]를 사용하여 특정 객체의 작은 이미지 세트에서 안정적 확산 공간 백본을 미세 조정하여 희귀 텍스트 토큰("sk")에 정체성을 연결합니다. 그런 다음 이전에 비디오로 조정된 안정적 확산(드림부쓰 없음)의 시간 계층을 원래 안정적 확산 모델의 새로운 드림부쓰 버전에 삽입하고 드림부쓰 훈련 이미지에 연결된 토큰을 사용하여 비디오를 생성합니다(부록 I.1.3의 그림 8 및 예제 참조). 저희는 드림부쓰 훈련 이미지의 정체성을 올바르게 캡처하는 개인화된 일관성 있는 비디오를 생성할 수 있음을 발견했습니다. 이를 통해 시간 계층이 다른 이미지 LDM으로 일반화됨을 검증합니다. 저희가 아는 한, 개인화된 텍스트-비디오 생성을 시연한 것은 저희가 처음입니다.

이 부분은 제가 아직 Dreambooth 논문을 읽어보지 않아 정확하게 이해하지 못해 원문을 그대로 번역해두었습니다.
5. Conclusions
지금까지의 내용을 정리해보도록 하겠습니다. VideoLDM에서 소개한 핵심적인 내용은 다음과 같습니다.
- 사전 학습된 LDM을 기반으로 함
- temporal한 layer를 추가하여 시간적인 정보를 사용할 수 있게 처리함
- 초기 S 개의 이미지를 기반으로 이후 동영상을 생성할 수 있는 조건을 추가함
- 프레임 사이의 보간 등을 추가한 모델을 제시함
- Upsampling DM을 통한 SR이 가능함
- 이 전체 프로세스에 대한 파이프라인을 설계함
- 추가로 드림부스 등을 통한 개인화된 text-to-video 처리가 가능함
이번 논문을 통해 비디오 생성을 어떻게 진행해야 하는지에 대한 개념을 이해할 수 있었습니다. 저는 이제 이 논문을 기반으로 공개한 stable video diffusion을 읽어볼 예정입니다.
마지막으로 엔비디아가 공개한 VideoLDM 샘플을 확인해보도록 하겠습니다.
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
https://research.nvidia.com/labs/toronto-ai/VideoLDM/
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
research.nvidia.com