
스테이블 디퓨전(Stable Diffusion) 등장 이후 이 모델을 기반으로 하는 다양한 방법들이 제시되었습니다. 이번에는 그 중 스테이블 디퓨전에 다양한 조건들을 어떻게 적용할지에 대해 연구한 ControlNet(Adding Conditional Control to Text-to-Image Diffusion Models)에 대해 리뷰해보겠습니다.
먼저
리뷰에 앞서 정확하게 어떤 모델인지 체험하기 위해 구현한 컨트롤넷 데모 영상을 보여드리겠습니다.
입력으로 이미지를 넣게 설정되어 있지만 자체적으로 오픈포즈만을 추출해서 사용합니다. 즉 아래 오픈포즈랑 텍스트만으로 그림을 생성한다고 보시면 됩니다.
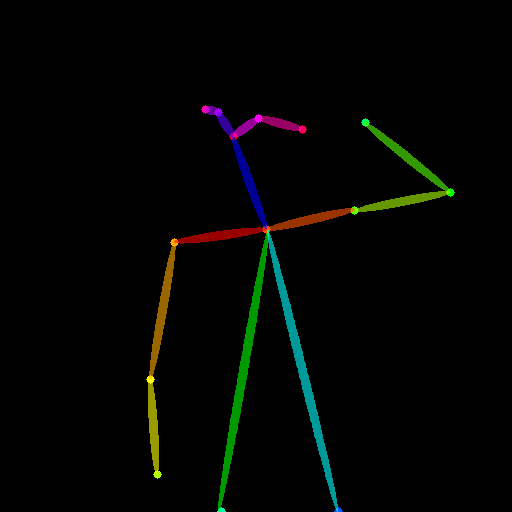
Introduction
스테이블 디퓨전의 등장 이후 이미지 생성 AI는 많은 발전을 이루었으며, 연구자뿐만 아니라 일반 사용자들까지 편하게 사용할 수 있을 정도로 대중적인 분야가 되었습니다. 이제는 생성형 AI를 통해 만들어 낸 이미지나 동영상이 유튜브, 인스타그램 등에 상당히 많이 보일 정도가 되었습니다. 다만 생성형 AI를 써본 분들은 알겠지만, 사용자가 원하는 이미지를 구성하기 위해 텍스트나 이미지를 주어 생성하는 것은 상당히 어려운 일인데요. 이러한 상황에서 텍스트 외의 다른 조건(Condition)들을 추가하여 생성하고자 연구한 방법이 ControlNet입니다.

이미지에 대해 텍스트만을 사용하여 생성하는 것이 아니라 위의 사진들의 왼쪽 1열처럼 캐니 엣지나 포즈를 조건으로 주어 해당 조건에 맞추어 이미지들을 생성하겠다는 방법이라고 볼 수 있습니다.
이 논문이 23년 2월에 공개되었는데요. 논문이 공개되자마자 다양한 사용자들(특히 디자이너들)이 사용하면서 결과물을 많이 공개했기 때문에 이런 방법이 있다는 것을 한번쯤은 보셨을 수 있을 것 같습니다. 참고로 지금은 이미 디자이너 관련 강의에서 어떻게 하이퍼파라미터를 설정하여 더 좋은 이미지를 뽑을지에 대해서도 알려줄 정도로 대중적인 기술이 되었습니다.
그렇다면 이제 논문을 살펴보도록 하겠습니다. 저는 논문의 3장 Method, 4장 Experiments 위주로 정리해보았습니다.
Method
ControlNet
기존의 스테이블 디퓨전을 공식으로 표현하면 다음과 같이 표현할 수 있습니다.
$$
y=\mathcal{F}(x;\Theta)
$$
이 공식은 인풋 $x$를 스테이블 디퓨전에 적용하여 결과값 $y$를 출력한다는 내용인데요. 여기서 $\Theta$는 파라미터를 의미합니다.
컨트롤넷은 여기서 기존 파라미터 $\Theta$를 Freeze하고, 학습 가능한 복사본 $\Theta_c$를 생성합니다. 이렇게 복사한 모델은 조건부 벡터 $c$를 받게 됩니다. 이 모델은 가중치를 Freeze한 원본 모델과 zero convolution을 통해 이어지게 되는데, 이 컨볼루전 레이어는 1x1 conv로 이루어져 있으며 초기 가중치가 0으로 초기화되어 있습니다. 제로 컨볼루젼은 총 2개가 존재하는데, 조건부 벡터 $c$를 학습가능한 모델에 적용하기 전에 하나가 존재하며, 학습가능한 모델에서 나온 결과를 원본 모델과 더할 때 하나가 더 존재합니다. 각각의 파라미터를 $\Theta_{z1}, \Theta_{z2}$라고 하며, 제로 컨볼루젼은 $\mathcal{Z}(\cdot;\cdot)$로 표현할 수 있습니다. 마지막으로 학습가능한 모델에 입력값으로 들어오는 값은 제로 컨볼루젼에 적용된 조건부 벡터 $c$와 인풋 노이즈 $x$의 합입니다.
따라서 조건부가 더해진 공식은 다음과 같이 표현할 수 있습니다.
$$
y_c = \mathcal{F}(x;\Theta) + \mathcal{Z}(\mathcal{F}(x+\mathcal{Z}(c;\Theta_{z1});\Theta_c);\Theta_{z2})
$$
이를 그림으로 표현하면 다음과 같습니다.
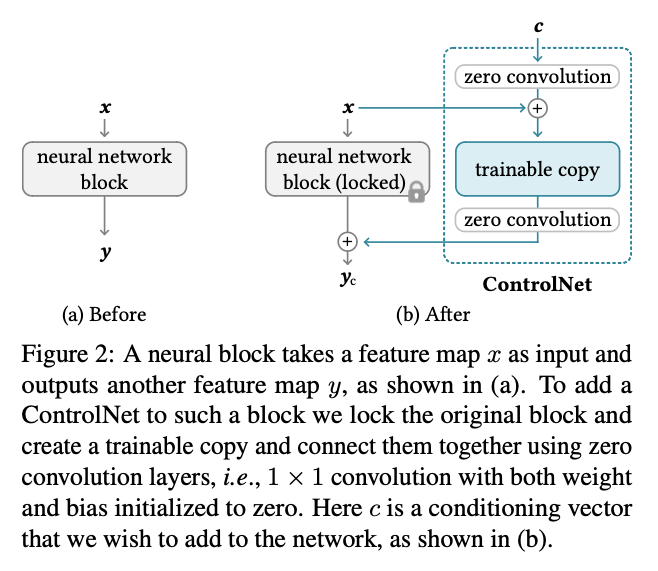
훈련의 첫 스텝에서는 제로 컨볼루젼의 가중치를 모두 0으로 초기화했기 때문에 위의 식의 우항이 모두 0으로 되어 $y=y_c$ 가 됩니다. 이러한 방식 덕에 유해한 노이즈는 훈련이 시작될 때에 영향을 미치지 않게 됩니다.
또한 인풋 노이즈 $x$는 훈련 가능한 모델에도 더해주기 때문에 훈련 가능한 모델은 강력한 백본 역할을 유지할 수 있습니다.
ControlNet for Text-to-Image Diffusion
스테이블 디퓨전은 기본적으로 VAE, U-Net, CLIP 등이 조합된 구조를 가지고 있는데요. 여기서 살펴볼 부분은 가장 중요한 부분인 U-Net입니다.
U-Net은 인코더 12블록, 디코더 12블록, 그리고 중간 블록 1개로 구성되어 있으며 총 25블록입니다. 이 중 8개의 블록은 다운샘플링 또는 업샘플링을 수행하는 레이어이며, 나머지 17 블록은 메인 블록입니다. 이 블록들은 각각 4개의 resnet layer, 2개의 ViT가 포함되어 있습니다. 여기서 ViT는 Cross Attention과 Self Attention 메커니즘이 포함되어 있습니다.
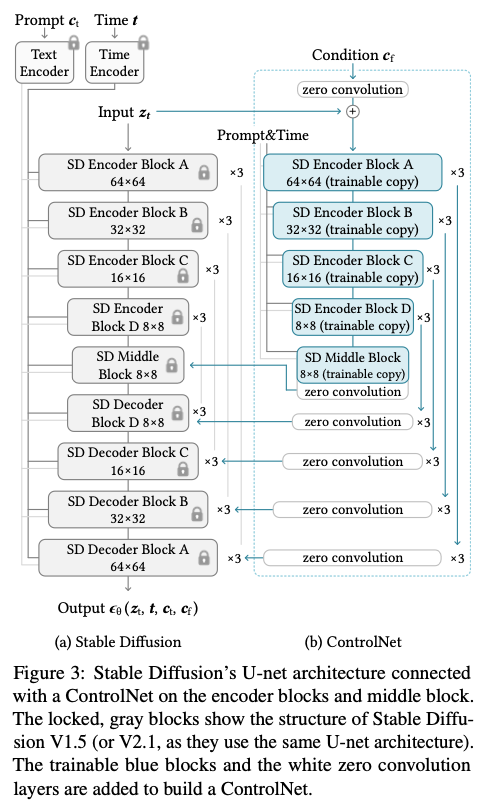
예를 들어 위의 그림에서 `SD Encoder Block A`는 4개의 resnet layer, 2개의 ViT를 포함되어 있으며 `x3`은 이 블록이 3번 반복된다는 의미입니다. 위의 그림에서 텍스트 프롬프트는 CLIP을 사용하며, diffusion timesteps은 Position Encoding을 사용하여 Time Encoder로 인코딩됩니다.
컨트롤넷은 U-Net의 각 인코더 레벨에 적용됩니다. 기존 스테이블 디퓨전의 U-Net 중 인코더 블록 12개와 미들 블록 1개에 대해 학습 가능한 복사본을 생성합니다. 12개 인코딩 블록은 4개의 해상도(64 × 64, 32 × 32, 16 × 16, 8 × 8)로 각각 하나씩 3번 복제됩니다. 출력은 U-net의 12개의 스킵 연결과 1개의 미들 블록에 추가됩니다. Stable Diffusion은 전형적인 U-Net 구조이기 때문에 본 ControlNet 구조는 다른 모델에도 적용 가능할 것으로 보입니다. 이 내용은 위 그림의 `(b) ControlNet`에서 자세히 확인할 수 있습니다.
이렇게 ControlNet을 연결하는 방법은 계산적으로 효율적이라고 합니다. 기존 모델은 프리징되어 있기 때문에 이 모델에 대해서는 기울기를 계산할 필요가 없기 때문입니다. 이러한 구조 덕에 일반적으로 스테이블 디퓨전을 최적화하는 것 대비 컨트롤넷을 최적화하는 것에 비해 약 23% 정도 더 많은 GPU, 34% 더 많은 시간 정도만 소요된다고 합니다.
마지막으로 조건부 이미지인 $c$에 대해 정리하도록 하겠습니다. 조건부 이미지 $c$는 스테이블 디퓨전의 입력 노이즈 크기와 일치해야 하기 때문에 512 x 512 크기를 64 x 64로 변환해야 합니다. 연구진은 4 x 4 커널과 2 x 2 스트라이드를 가진 4개의 간단한 컨볼루션 레이어를 사용하여 이를 인코딩했습니다. 채널의 크기는 각각 16, 32, 64, 128이고 ReLU를 사용했다고 합니다. 따라서 모델에 들어가는 컨디셔닝 벡터는 $c_f$로 표현하고, 공식은 다음과 같이 표현할 수 있습니다. 여기서의 $c_i$는 조건부 이미지를 말합니다.
$$
c_f = \mathcal{E}(c_i)
$$
Training
학습은 입력 이미지에 노이즈를 점진적으로 추가한 노이즈 벡터 $z_t$에 대해 모델 $\epsilon_0$를 사용하여 시점마다 추가된 노이즈를 예측하기 위해 수행됩니다. t는 노이즈가 추가된 횟수를 말합니다.
타임 스텝 $t$, 텍스트 프롬프트 $c_t$, 조건부 벡터 $c_f$ 노이즈 이미지인 $z_t$에 대해 로스는 다음과 같이 정의할 수 있습니다.
$$
\mathcal{L} = \mathbb{E}_{z_0,t,c_t,c_f,\epsilon\sim\mathcal{N}(0,1)}[\Vert\epsilon-\epsilon_0(z_t,t,c_t,c_f)\Vert^2_]
$$
연구진은 훈련 과정에서 무작위로 50%의 텍스트 프롬프트 $c_t$를 빈 문자열로 대체했다고 합니다. 이러한 방법 덕에 조건부 이미지의 의미를 이해하게끔 학습이 수행되었다고 합니다.
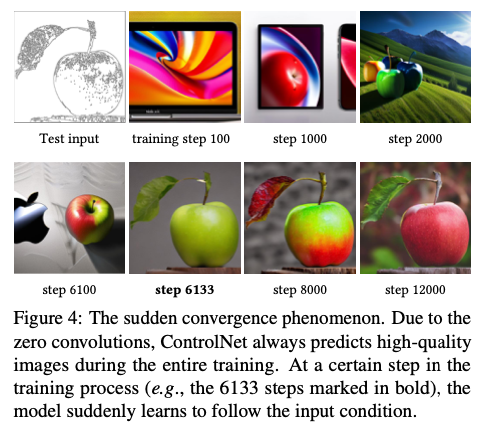
또한 모델을 학습하면서 연구진은 모델이 점진적으로 학습을 수행하는 것이 아닌 일반적으로 10K 미만의 최적화 단계에서 입력 컨디셔닝 이미지를 따라가는 데 갑자기 성공하는 것을 관찰했다고 합니다. 위의 이미지에서 확인할 수 있는데요. 저자는 이를 “sudden convergence phenomenon” 이라고 표현했습니다.
Inference
Classifier-free guidance resolution weighting
스테이블 디퓨전은 고품질 이미지를 생성하기 위해 Classifier-Free Guidance(CFG)라는 기술을 사용합니다. 이 기술은 다음과 같은 공식으로 이루어져 있습니다.
$$
\epsilon_{prd} = \epsilon_{uc} + \beta_{cfg}(\epsilon_c - \epsilon_{uc})
$$
여기서 $\epsilon_{prd}, \epsilon_{uc}, \epsilon_c, \beta_{cfg}$는 각각 모델의 최종 출력, unconditional 출력(조건 없이 출력한 값), 조건부 출력, 및 사용자가 지정하는 가중치입니다. `저는 여기서의 조건이 CLIP을 말하는 것으로 이해했습니다.`
컨트롤넷을 통해 여기에 조건부 이미지를 추가할 수 있는데요. $\epsilon_{uc}, \epsilon_c$ 모두에 추가하는 방법과 $\epsilon_c$에만 추가하는 두 가지 방법이 있습니다.
저자의 실험 결과 프롬프트가 없을 때 $\epsilon_{uc}, \epsilon_c$ 모두에 조건부 이미지를 추가할 경우 CFG 가이던스가 완전히 제거되어버렸고, $\epsilon_c$ 만 사용할 경우 가이던스가 매우 강력해졌다고 합니다. 이는 아래 이미지의 b, c에서 확인할 수 있습니다.

연구진은 $\epsilon_c$에만 조건부 이미지를 추가한 다음 스테이블 디퓨전과 컨트롤넷 사이의 각 연결에 가중치 $w_i$($w_i = 64/h_i$)를 곱하는 방법을 사용했습니다. 여기서 $h_i$는 $i$번째 블록의 크기(예: $h_1$ = 8, $h_2$ = 16, ..., $h_{13}$ = 64)입니다. CFG 가이던스 강도를 낮추면 그림 5d에 표시된 결과를 얻을 수 있으며, 저자는 이를 “CFG Resolution Weighting”라고 부르기로 했습니다
Composing multiple ControlNets

다수의 조건부 이미지를 적용하는 방법은 컨트롤넷의 출력을 그대로 스테이블 디퓨전에 더하는 방법이라고 합니다. 이러한 구성을 위해 추가적인 가중치 구성이나 보간법등이 필요하지 않습니다.
제가 확인했을 때에는 허깅페이스의 파이프라인에는 멀티컨트롤넷이 없어서 $\epsilon_c$를 여러개 더하는 방식으로 파이프라인을 뜯어서 테스트를 해 봤는데, 일단은 작동하는 것 같습니다.
Experiments
Qualitative Results
컨트롤넷은 Canny Edge, Depth Map, Normal Map, M-LSD lines, HED soft edge, ADE20K segmentation, Openpose, user sketches 와 같은 조건부 이미지를 입력으로 받을 수 있습니다.
아까 맨 처음에 보여드린 Figure 1이 조건부 이미지에 더해 텍스트 프롬프트 설정의 효과를 나타내는 그림이었고, 아래의 그림은 프롬프트가 없어도 강력한 성능의 이미지가 나온다는 결과입니다.

Ablative Study
저자는 다음과 같은 실험을 수행했습니다.
- 제로 컨볼루전을 0이 아닌 가우시안 초기화를 적용해보는 것
- 컨트롤넷이 아닌 ControlNet-lite라는 단일 컨볼루션망으로 대체해보는 것
실험에 사용할 프롬프트는 4가지로 나누었습니다.
- 프롬프트 없이 수행
- 불충분한 프롬프트(예: "고품질, 상세, 전문적인 이미지")
- 조건부 이미지와는 다른 프롬프트(예: 멋진 집 조건부 이미지에 대해 맛있는 케이크라고 명시)
- 필요한 콘텐츠 의미론을 설명하는 완벽한 프롬프트(예: "멋진 집")

위의 그림의 좌측 행 (a)(b)(c)가 첫 실험을 나타내며 오른쪽 열이 아래 실험을 나타냅니다. 참고로 맨 처음 (a)는 일반적인 컨트롤넷을 의미하고 (b)가 가우시안 초기화, (c)가 컨트롤넷-라이트입니다.
컨트롤넷은 4가지 프롬프트 설정에서 성공하는 것을 확인할 수 있으며, 나머지는 모두 이상해지는 것을 확인할 수 있습니다.
Quantitative Evaluation
연구진은 몇 개의 과제에 대해 정량적인 평가를 진행해보았습니다.
User study
20개의 unseen hand-drawn sketches에 대해 PITI, SGD 등의 모델과 비교했습니다. 12명의 사용자를 초대하여 "표시된 이미지의 품질"과 "스케치의 충실도" 측면에서 5가지 결과로 구성된 20개 그룹의 순위를 개별적으로 매겼고 이러한 방식으로 결과 품질에 대해 100개, 조건 충실도에 대해 100개의 순위를 얻습니다. 이 방법은 사용자가 각 결과를 1~5개의 척도로 순위를 매기는 선호도 메트릭으로 평균 유저 순위(AUR)라고 표현했습니다.
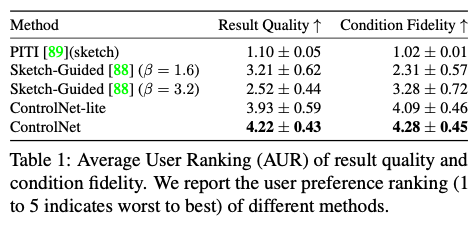
결과는 위와 같습니다. 다른 모델에 비해 상당히 높은 것을 확인할 수 있습니다.
Comparison to industrial models
Stable Diffusion V2 Depth 2 Image은 대규모의 A100으로 수천 시간을 사용했으며, 12M 이상의 훈련 데이터로 훈련한 모델입니다. 연구진은 동일한 Depth 조건으로 SDV2용 컨트롤넷을 훈련했고 200k 정도의 적은 데이터, 단일 3090Ti GPU, 5일 정도의 훈련을 진행했습니다.
그 후 각 SDv2-D2I 및 ControlNet에서 생성된 이미지 100개를 사용하여 12명의 사용자에게 두 가지 방법을 구별하도록 요청한 결과 사용자의 평균 정밀도는 0.52 ± 0.17로 두 방법이 거의 구별할 수 없는 결과를 도출했다고 합니다.
Condition reconstruction and FID score
저자는 ADE20K 데이터를 사용하여 conditioning fidelity(조건부 충실도)를 평가했습니다. OneFormer라는 SOTA 세그멘테이션 방법을 사용하여 실제 정답지의 IoU를 보면 0.58이 나오는데요. 컨트롤넷에 조건부 이미지로 세그멘테이션을 주었을 때 정답지와 가장 비슷한 0.35 수준의 이미지를 생성하는 것을 확인했습니다.

또한 Frechet Inception Distance(FID)을 사용하여 세그멘테이션을 조건으로 준 생성 이미지와 원본 이미지 간의 분포 거리를 비교해보았는데요. 상당히 높은 점수를 달성한 것을 확인할 수 있습니다.
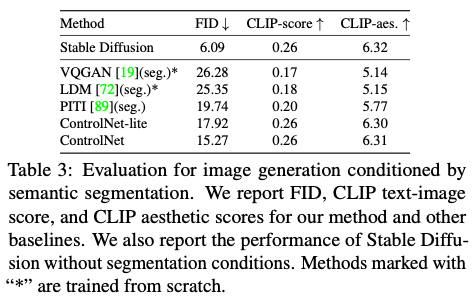
추가로 확인한 CLIP-score, CLIP-aes도 상당히 높은 것을 확인할 수 있습니다. 참고로 CLIP score는 이미지와 텍스트 간의 일치도를 확인하는 방법이고, CLIP aesthetic score는 이미지의 미적 품질과 텍스트의 미적 품질에 대한 설명(예: 아름다운, 멋진) 사이의 일치도를 확인하는 방법입니다.
FID는 이미지가 얼마나 사실적인지에 대한 지표라고 볼 수 있는데요. Stable Diffusion을 함께 표에 제시한 이유를 생각해보니, 조건 없이 생성한 스테이블 디퓨전의 FID와 제일 유사할 정도로 사실적인 이미지를 만들었다는 의미로 보입니다.
Comparison to Previous Methods
연구진은 PITI, Sketch-Guided Diffusion, Taming Transformers 등의 최근 모델들과 비교를 진행해보았습니다. (PITI의 backbone은 시각적 품질과 성능이 다른 OpenAI GLIDE를 사용했다고 합니다.)
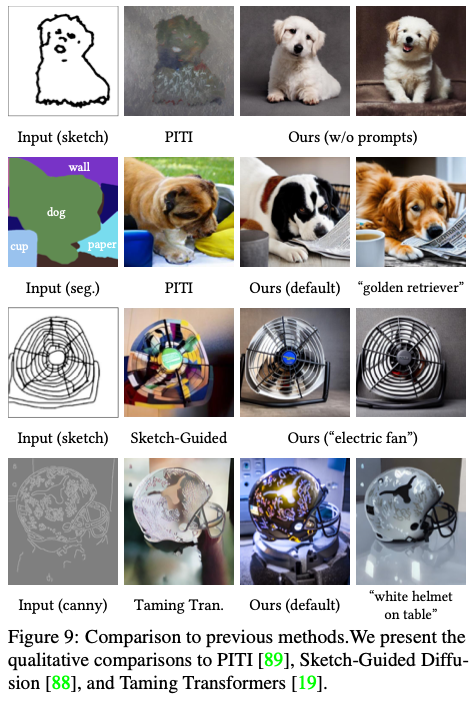
기존 모델들보다 더 좋은 모습을 보여주는 것 같습니다. 특히 스케치에 대해서도 잘 생성하는 것이 돋보이네요.
Discussion
마지막으로 연구진은 몇 가지 논의점에 대해 정리했습니다.
Influence of training dataset sizes

위의 그림에서 볼 수 있듯이 컨트롤넷은 1k 정도의 이미지로 학습을 진행해도 조건부에 맞추어 잘 생성하고 있는 것을 확인할 수 있습니다. 또한 데이터가 증가될수록 성능이 좋아지는 것 역시 확인할 수 있습니다.
Capability to interpret contents

위의 그림처럼 조건부 이미지의 의미를 추론하는 능력 역시 좋은 것을 확인했습니다.
Transferring to community models
저자는 컨트롤넷이 프리트레이닝된 스테이블 디퓨전 모델의 네트워크 토플로지를 변경하지 않기 때문에 아래 그림처럼 Comic Diffusion, Pro-to-gen 3.4과 같은 다양한 스테이블 디퓨전 모델에 적용할 수 있다고 설명하고 있습니다.

저는 컨트롤넷의 초기 가중치는 원본 스테이블 디퓨전의 가중치이므로, 스테이블 디퓨전만 바꿔끼면 이게 가능할까 싶었는데요. 실제 몇 가지 케이스를 적용해보니 잘 적용되는 것을 확인했습니다.
결론
지금까지 컨트롤넷을 살펴보았습니다. (1) 다양한 조건을 이미지화 해서 넣는다는 아이디어, (2) 이 조건을 다른 인코더로 구현하여 인풋으로 넣는 아이디어 (3) 제로 컨볼루션 등 창의적이고 다양한 아이디어로 만들어진 좋은 모델인 것 같습니다.
저자가 설명한 여러가지 조건을 그냥 더하는 부분과, 추가적인 학습 없이 다른 SD 모델에 적용할 수 있다는 부분은 직관적으로 잘 이해가 되지 않는데요. 만약 이런 부분들이 정말 제 생각처럼 잘 구현되어 있다면 상당히 자주 쓰일 모델이 될 것 같습니다.
참고
[1] ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models