
-
소개
-
3. Method
-
3.1. Method overview
-
3.2. Pose preservation and temporal consistency
-
3.3. Conditional generative adversarial networks
-
3.4. Identity guidance
-
4. Experiments
-
4.1. Implementation details
-
4.2. Evaluation metrics
-
4.3. Ablation Study
-
4.4. Quantitative results
-
4.5. Visual quality of the results
-
5. Conclusions and Future Work
소개
https://arxiv.org/abs/2005.09544
CIAGAN: Conditional Identity Anonymization Generative Adversarial Networks
The unprecedented increase in the usage of computer vision technology in society goes hand in hand with an increased concern in data privacy. In many real-world scenarios like people tracking or action recognition, it is important to be able to process the
arxiv.org
저는 스테이블 디퓨전을 사용한 비식별화를 연구하고 있는데요. 스테이블 디퓨전을 사용한 비식별화는 아직 연구 초기 단계이다보니 우선은 이전 SOTA급인 GAN 기반 연구를 살펴보고자 합니다. CIAGAN은 StyleGAN을 이용한 최신 논문보다는 성능이 조금 떨어질 수는 있으나 조건부 이미지와 신원을 임베딩으로 넣는 기법을 보여준 논문입니다.
CIAGAN의 저자가 생각하는 비식별화 모델의 목표는 5가지라고 합니다. 이러한 목표를 어떻게 해결했는지 논문을 보며 확인해보겠습니다. 본 포스팅에서는 논문의 3,4장을 다루고 있습니다.
비식별화 모델의 목표
(i) 익명화: 생성된 출력물은 원래 이미지에서 사람의 신원을 숨겨야 합니다.
(ii) 제어: 생성된 이미지의 가짜 신원은 제어 벡터에 의해 제어되므로 실제 사람-가짜 신원 매핑을 완전히 제어할 수 있습니다.
(iii) New Identity: 생성된 이미지는 교육 세트에 존재하지 않는 새로운 ID만 포함해야 합니다.
(iv) 사실적: 최첨단 감지 및 인식 시스템에서 사용하기 위해서는 출력 이미지가 사실적으로 보여야 합니다.
(v) 시간적 일관성: 사람들의 추적이나 행동 인식과 같은 작업을 위해 비디오의 시간적 일관성과 포즈 보존이 보장되어야 합니다.
3. Method
3.1. Method overview
전체적인 아키텍쳐는 다음과 같습니다.
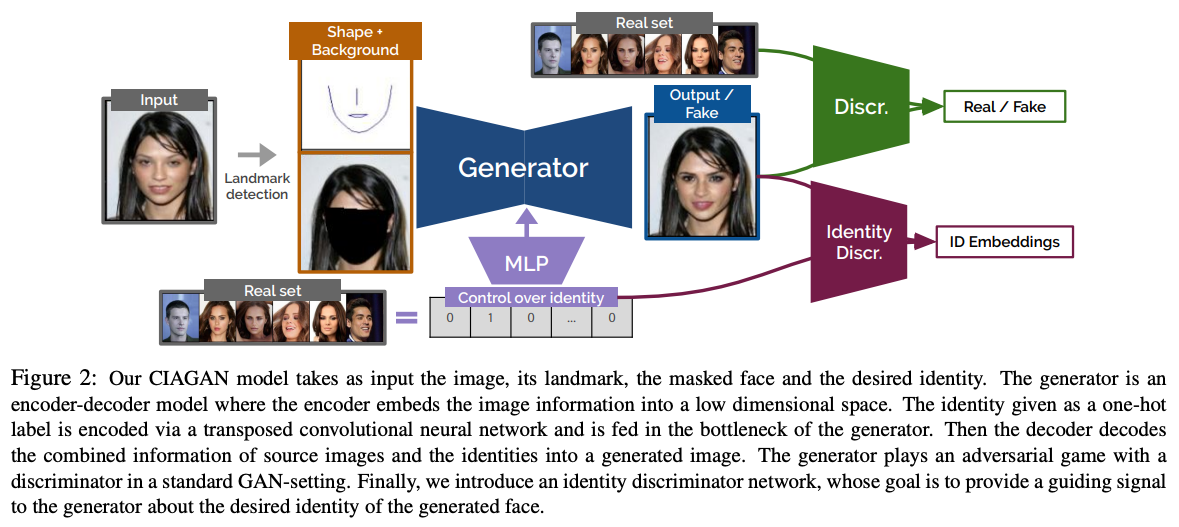
제너레이터가 조건부 이미지를 입력으로 받는 인코더-디코더 형태의 모델인 걸 확인할 수 있고, 아래에 identity를 제너레이터의 중간 부분에 적용해주는 Discriminator 관련 부분이 있는 것을 확인할 수 있습니다.
CIAGAN의 주요 구성요소는 다음과 같습니다.
Pose preservation and temporal consistency
포즈의 보존 및 시간적 일관성을 제공하기 위해 입력 얼굴 또는 신체의 랜드마크를 사용했습니다. 이는 추적 등에 유용하게 사용 가능한 포즈 보존을 보장하고, 비디오 작업 시 시간적인 일관성을 유지할 수 있는 방법입니다.
Conditional GAN
조건을 적용한 GAN을 사용했습니다. 조건으로 사용한 것은 랜드마크로, Generator가 생성한 이미지의 현실성을 Discriminator가 판별하는 방식으로 학습했습니다.
Identity guidance discriminator
CIAGAN에서는 일반적인 Discriminator 외에 또 다른 Discriminator가 존재합니다. 이 모듈은 Generator가 주입하는 identity 특성을 제어하는 역할을 수행합니다.
3.2. Pose preservation and temporal consistency
예전의 비식별화 방법들은 익명화할 얼굴의 RGB 이미지를 입력으로 받는데, 얼굴의 신원이 익명화되지 않는 문제가 발생할 수 있습니다.
Landmark image
이렇게 생성한 얼굴이 원래 신원과 연결되지 않도록 하기 위해 얼굴에 대한 랜드마크를 사용했습니다. 이는 아래와 같은 장점을 가질 수 있습니다.
- 랜드마크 이미지에 신원 정보가 거의 남지 않은 얼굴의 희소한 표현이 포함되어 있어 신원 유출을 방지하고,
- 생성기가 얼굴 모양에 맞게 조절되어 출력에서 입력 포즈를 보존할 수 있습니다.
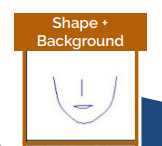
가능한 한 많은 신원 정보를 숨기면서도 포즈를 유지하기 위해 모든 랜드마크를 사용하지 않고 위 그림과 같이 일부 랜드마크만을 사용했습니다.
Masked background image
이 모델의 목표는 이미지의 얼굴 영역만 생성하여 원래 이미지 배경에 인페인팅하는 것이기 때문에, 얼굴 영역을 마스킹 한 배경 이미지를 조건으로 추가했습니다. 이를 통해 알고리즘은 (배경이 아닌) 얼굴 생성에 학습력을 집중할 수 있으며, 동시에 감지 또는 추적 알고리즘을 방해할 수 있는 배경 변경이 없음을 보장할 수 있게 됩니다. 마스크된 배경 이미지에는 여전히 머리의 이마 영역이 포함되어 있습니다. 생성기가 이 정보에 액세스하면 생성된 얼굴의 피부 외관을 이마 피부색에 일치시키는 방법을 학습할 수 있습니다. 동일한 이미지에 여러 얼굴이 있는 경우 이미지에서 각 얼굴을 감지하고 순차적으로 익명화 프레임워크를 적용합니다.
Temporal consistency
비디오 작업을 위해 모든 비익명화 파이프라인은 비디오 시퀀스에서 생성된 이미지의 시간적 일관성을 보장해야 합니다. 최신 모델은 프레임 간의 광학 흐름을 조건으로 하는 판별기를 사용하여 이러한 시간적 일관성을 보장하였습니다. 이런
비디오 작업을 위해 모든 비익명화 파이프라인은 비디오 시퀀스에서 생성된 이미지의 시간적 일관성을 보장해야 합니다. 최첨단 비디오 번역 모델[39]은 해당 프레임 간의 optical flow를 조건으로 하는 판별기를 사용하여 시간적 일관성을 보장합니다. optical flow는 외부 신경망을 통해 계산되며, 이는 높은 게산 비용과 복잡한 프레임워크를 발생시킵니다. CIAGAN에서는 랜드마크에 대해 spline interpolation을 통해 처리를 하여 시간적 일관성을 얻고 있습니다. 따라서 CIAGAN은 동일한 프레임워크를 사용하여 이미지와 비디오에 대한 비식별화를 수행할 수 있으며, 유일한 차이는 보간이 필요하다는 점입니다.
3.3. Conditional generative adversarial networks
GAN framework
간단한 용어로, GAN은 두 개의 신경망, 즉 현실적으로 보이는 샘플을 생성하는 것을 목표로 하는 생성기 G와 실제 샘플과 생성된 샘플을 구별하는 것을 목표로 하는 판별기 D를 결합합니다. 네트워크는 적대적 방식으로 훈련되며, D는 훈련 및 생성된 예제 모두에 올바른 레이블을 할당할 확률을 최대화하도록 훈련되고, G는 D가 생성된 샘플에 대한 올바른 레이블을 예측할 확률을 최소화하도록 훈련됩니다. 즉, D는 생성된 샘플과 실제 샘플을 분리하는 방법을 학습하는 반면, G는 D를 속여서 생성된 샘플을 실제 샘플로 분류하는 방법을 학습합니다. GAN 훈련이 어렵고 많은 트릭이 필요하다는 것은 잘 알려져 있습니다. 이 작업에서는 LSGAN 손실 함수를 사용하여 CIAGAN을 훈련하기로 선택합니다.
GAN 훈련에 최소 제곱 손실 함수를 사용하는 아이디어는 간단하면서도 강력합니다. 최소 제곱 손실 함수는 올바르게 분류되었지만 여전히 실제 샘플에서 멀리 떨어져 있는 샘플도 처벌하기 때문에 가짜 샘플을 결정 경계로 이동할 수 있습니다. 이는 대부분 잘못 분류된 샘플에 불이익을 주는 교차 엔트로피 손실과 반대됩니다. 이 속성을 기반으로 LSGAN은 실제 데이터에 더 가까운 샘플을 생성할 수 있습니다. LSGAN 설정에서 판별기의 목적 함수는 다음과 같이 정의됩니다:
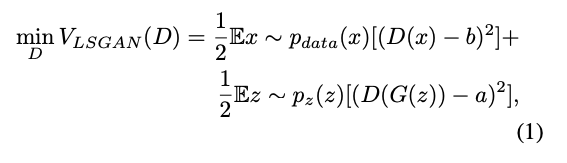
여기서 a와 b는 가짜 데이터와 진짜 데이터의 레이블입니다. 생성기의 손실은 다음과 같이 정의됩니다:
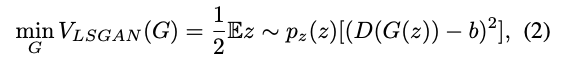
LSGAN은 GAN 훈련에 사용되는 다른 일반적인 손실 함수로 대체할 수 있습니다.
Conditional GAN
일반적인 GAN은 무작위 노이즈 벡터를 입력으로 생성기를 학습하는데요. CIAGAN의 경우 포즈 보존 및 시간적 일관성을 위해 생성된 얼굴을 입력 이미지의 랜드마크와 정렬해야 하며, 배경에 대한 정보도 중요합니다. 따라서 조건부 GAN 프레임워크를 사용하였습니다. 구체적으로 입력으로 랜드마크와 마스크된 이미지(배경)을 넣는 인코더-디코더 구조의 아키텍쳐를 적용하였습니다. 인코더는 랜드마크와 마스크된 이미지를 저차원 표현(병목)으로 가져와 디코더가 결합된 표현을 취하고 이를 업샘플링하여 익명화된 RGB 이미지를 생성합니다.
3.4. Identity guidance
랜드마크 등을 입력으로 하였을 때에도 모델이 빠르게 학습 데이터에 오버피팅되는 경향이 있었다고 합니다. 이렇게 될 경우 결국 원래 얼굴과 유사한 얼굴울 생성하게 되어 비식별화 목적이 사라지게 되기 때문에, 이 문제를 해결하기 위해 Identity guidance discriminator를 학습하였다고 합니다. 이 판별기는 주어진 실제 이미지에 대해 생성할 이미지의 원하는 신원을 무작위로 선택하는 역할을 합니다.
이 Identity는 One-Hot 벡터로 표현되며, 생성자의 bottleneck 부분에 입력값으로 들어가게 됩니다. 이러한 방식으로 생성기는 실제 이미지의 포즈를 유지하면서 원하는 아이덴티티의 일부 특성을 가진 얼굴을 생성하는 방법을 학습합니다. 즉, 생성된 이미지는 랜드마크 아이덴티티와 원하는 아이덴티티 모두가 적용된 이미지입니다. 여기서 생성된 이미지가 비식별화되기를 원한다면 생성된 이미지의 ID가 실제 ID와 동일하지 않아야 합니다.
신원 판별기는 Proxy-NCA loss을 사용하여 사전 훈련된 샴 신경망으로 설계되었습니다. 사전 훈련은 실제 이미지를 사용하여 수행되며, 여기서 판별자는 동일한 정체성에 속하는 이미지의 특징을 결합하도록 훈련됩니다. 신원 판별기의 목표는 생성기에 안내 신호를 제공하여 특정 신원의 표현 특징과 유사한 이미지를 생성하도록 안내하는 것입니다.
The case for multiple object tracking
특히 흥미로운 것은 가짜 신원 생성에 대한 통제입니다. 우리는 카메라에서 가져온 시퀀스(예: 여러 개의 객체 추적) 내에서 동일한 실제 사람-가짜 신원 매핑을 유지할 수 있어야 하지만 동시에 데이터의 장기 추적 및 잠재적인 오용을 피하기 위해 다른 카메라에 대한 매핑을 변경할 수 있어야 합니다. 그렇게 하기 위해, 한 사람이 한 카메라에서 다른 카메라로 이동할 때, 우리는 그 제어 벡터를 새로운 카메라로 대체하고, 그 사람에게 새로운 신원을 제공합니다. 이것은 장기 추적의 바람직하지 않은 결과 없이 카메라에서 가져온 프레임 내에서 여러 개의 객체 추적을 수행하는 간단하지만 강력한 방법입니다.
이 부분은 정확하게 이해는 안가지만 동일 카메라 내의 영상에서는 동일 신원을 그대로 유지하고, 다른 카메라의 영상에서는 새로운 신원이 유지된다는 내용으로 보이는데, 데이터가 달라지면 다시 신원이 매핑되는게 당연한게 아닌가 싶기도 하고 이해를 잘못했나 싶기도 하고 그렇습니다.
4. Experiments
Datasets
CIAGAN은 3개의 데이터셋을 사용하였습니다.
- CelebA : 데이터 세트는 10,177개의 고유한 ID로 구성된 202,599개의 얼굴 이미지입니다. 저자는 정렬된 버전을 사용하여 각 이미지가 사람의 눈 사이의 한 점에 중심을 두고 원래 얼굴 비율을 유지하면서 178 × 218 해상도로 패딩 및 크기를 조정했습니다. 각 ID에는 최대 35개의 사진이 포함됩니다. 얼굴 랜드마크는 HOG를 사용하여 추출했습니다.
- MOTS : 이 데이터셋에서는 얼굴 랜드마크를 사용하는 대신 신체 분할 마스크를 사용합니다. 데이터 세트는 1,595명의 서로 다른 사람들의 3,425개의 비디오로 구성됩니다.
- Labeled Faces in the Wild (LFW) : 이 데이터 세트는 10개로 스플릿된 6,000개의 쌍 이미지로 구성되며, 여기서 쌍의 절반은 동일한 정체성의 이미지를 포함하고 나머지 쌍은 서로 다른 정체성을 가진 이미지로 구성됩니다.
Baselines
일반적인 비식별화 기법 및 기존 모델과 비교를 진행했습니다.
- Simple Anonymization methods : 얼굴의 픽셀화, 블러 및 마스킹과의 비교를 수행했습니다.
우리는 얼굴의 픽셀화, 블러 및 마스킹을 사용하고 우리의 방법과 비교합니다. - Image Translation methods : 공식 pix2pix, CycleGAN과 비교를 진행했습니다.
- Face Replacement methods : Sota 모델과 비교를 진행했습니다.
4.1. Implementation details
저자는 랜드마크 및 얼굴 마스크에 대해 Dlib-ml 라이브러리를 사용하여 생성하였습니다. 학습 이미지는 128x128 해상도로 맞추어 훈련하였고 생성기 모델의 아키텍쳐는 U-Net입니다. identity branches의 피쳐는 bottleneck에서 연결됩니다.
판별기를 위해 identity guidance network와 동일한 아키텍쳐를 가진 표준 컨볼루젼망을 사용했고, learning rate 1e-5, Adam, 60 에포크 동안 훈련을 진행했습니다. $\beta_1, \beta_2$는 0.5, 0.9로 설정하였습니다. 모델의 훈련은 단일 GPU 기준 하루 정도 소요되었습니다. 세부적인 내용은 논문 끝의 보충 자료에서 확인할 수 있습니다.
4.2. Evaluation metrics
HOG, SSH를 통해 얼굴 감지를 수행하였고, 감지된 얼굴의 백분율을 사용하여 성능을 평가하였습니다.
재식별을 위해 Proxy-NCA를 사용하여 샴 네트워크를 훈련하였고, Inception-Resnet backbone 기반의 FaceNet을 사용하였습니다. 재식별에는 Recall@1을 사용하여 평가를 수행했습니다. 이 메트릭은 0~100 사이의 값을 가지고 있으며 0일 경우 완벽한 비식별율, 100일 경우 완벽한 식별율을 나타냅니다.
마지막으로 FID를 사용하여 정량적으로 시각적인 품질을 체크하였습니다.
4.3. Ablation Study
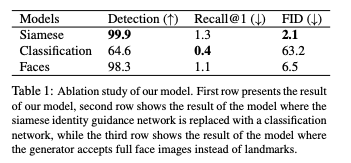
위의 표에서는 ID 판별기를 기본적인 샴 네트워크를 사용한 버전과, 일반적인 분류기를 사용한 버전, 세번째는 랜드마크를 입력으로 받지 않고 전체 얼굴을 입력으로 받는 버전에 대한 연구를 수행했습니다. 분류기를 변경할 경우 탐지율이 떨어지는 걸 확인할 수 있고, 랜드마크 대신 전체 얼굴을 넣을 때에도 오히려 더 낮은 점수를 보이는 걸 확인할 수 있습니다.
4.4. Quantitative results
Detection and Recognition
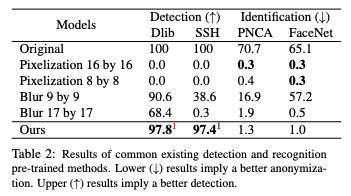
비식별화 결과는 높은 얼굴 탐지율과 낮은 신원 식별률이 필요한데요. 다른 비식별화 방법들에 비해 높은 탐지율과 낮은 식별률을 달성한 걸 확인할 수 있습니다.
Recognition based on landmarks
이번에는 랜드마크만을 입력으로 받았을 때에 대해 테스트를 진행해보았습니다. 랜드마크만을 식별 모델에 넣을 경우 70.7 → 30.5% 정도의 성능을 보이는데요. 비식별화를 진행한 후의 얼굴에서 랜드마크를 추출하여 식별자를 평가할 경우 1.9% 정도의 성능이 나온다고 합니다.
이 부분은 무엇을 목적으로 실험한 건지 이해가 잘 안되네요.
Are we just doing face swapping?

저자는 identity guidance network를 통해 페이스 스와핑만 이루어진것이 아닌가에 대한 확인을 진행했는데, 위의 그림과 같이 다행히도 생성된 이미지가 주어진 아이덴티티(인종 또는 성별)의 높은 수준의 특성을 취하지만 해당 아이덴티티의 실제 이미지와는 크게 다르다는 것을 확인할 수 있었다고 합니다.
4.4.1 Comparison to SOTA in de-identification
LFW 데이터에 대해 SOTA 논문과 비교를 진행했습니다. VGGFace2, CASIA-Webface에서 사전 학습된 FaceNet을 식별 모델로 사용했습니다.
평가 지표는 true acceptance rate으로 최대 0.001 비율의 거짓 양성에 대한 참 양성의 비율입니다.
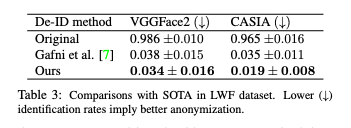
실제 얼굴은 0.99 수준의 완벽한 식별률을 보이는 것을 확인할 수 있고, SOTA와 비교해 본 결과 VGGFace2에서는 0.04, CASIA에서는 0.016 정도로 더 좋은 성능을 보이는 걸 확인할 수 있습니다.
평균적으로 CIAGAN은 첫 번째 데이터 세트에서 10.5%의 비식별률을, 두 번째 데이터 세트에서 45.7%의 비식별률을 보여주면서도 99.13%의 높은 탐지율을 유지합니다. 평균 2.65%의 참 양성률은 결함이 거의 없는 시스템도 CIAGAN 처리된 데이터에서 진정한 정체성을 완전히 찾지 못할 것임을 보여줌으로써 이미지 익명화를 달성하는 데 있어 CIAGAN이 강점이 있다는 걸 확인할 수 있습니다.
4.5. Visual quality of the results
CIAGAN의 FID는 4.3에서 소개한 표와 같이 2.08 정도로 기존 방법들보다 좋은 성능을 보이고 있습니다.

또한 위의 그림과 같이 신원 판별기의 제어 벡터가 변경될 때 생성된 이미지의 다양성을 확인해 볼 수 있었습니다.

Figure 4에서는 다른 SOTA와의 시각적 성능 비교를 확인할 수 있으며

Figure 5에서는 시간적 일관성이 있다는 것을 확인할 수 있었습니다.
저자는 모든 경우에 포즈가 보존되어 뛰어난 시간적 일관성을 얻을 수 있었고, 동시에 랜드마크와 함께 작동하는 CIAGAN 버전이 전체 얼굴에서 훈련된 버전보다 더 나은 이미지를 생성한다는 것을 확인했다고 합니다.

마지막으로, Figure 6은 전신에 대한 비식별화를 실험해보았는데요. 각 행의 첫 번째 이미지는 원본 이미지로 나머지는 생성된 비식별화 이미지입니다. 자세 정도는 잘 유지하지만 색이나 신체 등에서는 잘 안되는것을 확인할 수 있습니다.
5. Conclusions and Future Work
마지막으로 저자의 결론을 정리해보도록 하겠습니다. 이 논문에서 저자는 이미지와 비디오의 얼굴 및 신체 익명화 프레임워크를 제안했습니다. 저자의 새로운 CIAGAN 모델은 조건부 생성 적대 네트워크를 기반으로 하며, 얼굴은 샴 네트워크가 제공하는 안내 신원 신호를 기반으로 익명화됩니다. 이러한 방법은 생성된 이미지에서 큰 다양성을 보여주면서 비식별화에서 최첨단을 능가한다는 것을 보여주었습니다.
제가 현재 가진 의문점은 “생성형 모델이 학습을 수행할 때 원본과 같게끔 학습을 수행할텐데, 성능이 너무 높아진다면 비식별화라고 볼 수 있을까?” 인데요. 이 논문은 이러한 문제를 Identity guidance discriminator를 사용하여 다른 신원 특징까지 함께 입력으로 받아 이미지를 생성하는 방식으로 해결하고자 했다는 점을 확인할 수 있었습니다.
소개
https://arxiv.org/abs/2005.09544
CIAGAN: Conditional Identity Anonymization Generative Adversarial Networks
The unprecedented increase in the usage of computer vision technology in society goes hand in hand with an increased concern in data privacy. In many real-world scenarios like people tracking or action recognition, it is important to be able to process the
arxiv.org
저는 스테이블 디퓨전을 사용한 비식별화를 연구하고 있는데요. 스테이블 디퓨전을 사용한 비식별화는 아직 연구 초기 단계이다보니 우선은 이전 SOTA급인 GAN 기반 연구를 살펴보고자 합니다. CIAGAN은 StyleGAN을 이용한 최신 논문보다는 성능이 조금 떨어질 수는 있으나 조건부 이미지와 신원을 임베딩으로 넣는 기법을 보여준 논문입니다.
CIAGAN의 저자가 생각하는 비식별화 모델의 목표는 5가지라고 합니다. 이러한 목표를 어떻게 해결했는지 논문을 보며 확인해보겠습니다. 본 포스팅에서는 논문의 3,4장을 다루고 있습니다.
비식별화 모델의 목표
(i) 익명화: 생성된 출력물은 원래 이미지에서 사람의 신원을 숨겨야 합니다.
(ii) 제어: 생성된 이미지의 가짜 신원은 제어 벡터에 의해 제어되므로 실제 사람-가짜 신원 매핑을 완전히 제어할 수 있습니다.
(iii) New Identity: 생성된 이미지는 교육 세트에 존재하지 않는 새로운 ID만 포함해야 합니다.
(iv) 사실적: 최첨단 감지 및 인식 시스템에서 사용하기 위해서는 출력 이미지가 사실적으로 보여야 합니다.
(v) 시간적 일관성: 사람들의 추적이나 행동 인식과 같은 작업을 위해 비디오의 시간적 일관성과 포즈 보존이 보장되어야 합니다.
3. Method
3.1. Method overview
전체적인 아키텍쳐는 다음과 같습니다.
제너레이터가 조건부 이미지를 입력으로 받는 인코더-디코더 형태의 모델인 걸 확인할 수 있고, 아래에 identity를 제너레이터의 중간 부분에 적용해주는 Discriminator 관련 부분이 있는 것을 확인할 수 있습니다.
CIAGAN의 주요 구성요소는 다음과 같습니다.
Pose preservation and temporal consistency
포즈의 보존 및 시간적 일관성을 제공하기 위해 입력 얼굴 또는 신체의 랜드마크를 사용했습니다. 이는 추적 등에 유용하게 사용 가능한 포즈 보존을 보장하고, 비디오 작업 시 시간적인 일관성을 유지할 수 있는 방법입니다.
Conditional GAN
조건을 적용한 GAN을 사용했습니다. 조건으로 사용한 것은 랜드마크로, Generator가 생성한 이미지의 현실성을 Discriminator가 판별하는 방식으로 학습했습니다.
Identity guidance discriminator
CIAGAN에서는 일반적인 Discriminator 외에 또 다른 Discriminator가 존재합니다. 이 모듈은 Generator가 주입하는 identity 특성을 제어하는 역할을 수행합니다.
3.2. Pose preservation and temporal consistency
예전의 비식별화 방법들은 익명화할 얼굴의 RGB 이미지를 입력으로 받는데, 얼굴의 신원이 익명화되지 않는 문제가 발생할 수 있습니다.
Landmark image
이렇게 생성한 얼굴이 원래 신원과 연결되지 않도록 하기 위해 얼굴에 대한 랜드마크를 사용했습니다. 이는 아래와 같은 장점을 가질 수 있습니다.
- 랜드마크 이미지에 신원 정보가 거의 남지 않은 얼굴의 희소한 표현이 포함되어 있어 신원 유출을 방지하고,
- 생성기가 얼굴 모양에 맞게 조절되어 출력에서 입력 포즈를 보존할 수 있습니다.
가능한 한 많은 신원 정보를 숨기면서도 포즈를 유지하기 위해 모든 랜드마크를 사용하지 않고 위 그림과 같이 일부 랜드마크만을 사용했습니다.
Masked background image
이 모델의 목표는 이미지의 얼굴 영역만 생성하여 원래 이미지 배경에 인페인팅하는 것이기 때문에, 얼굴 영역을 마스킹 한 배경 이미지를 조건으로 추가했습니다. 이를 통해 알고리즘은 (배경이 아닌) 얼굴 생성에 학습력을 집중할 수 있으며, 동시에 감지 또는 추적 알고리즘을 방해할 수 있는 배경 변경이 없음을 보장할 수 있게 됩니다. 마스크된 배경 이미지에는 여전히 머리의 이마 영역이 포함되어 있습니다. 생성기가 이 정보에 액세스하면 생성된 얼굴의 피부 외관을 이마 피부색에 일치시키는 방법을 학습할 수 있습니다. 동일한 이미지에 여러 얼굴이 있는 경우 이미지에서 각 얼굴을 감지하고 순차적으로 익명화 프레임워크를 적용합니다.
Temporal consistency
비디오 작업을 위해 모든 비익명화 파이프라인은 비디오 시퀀스에서 생성된 이미지의 시간적 일관성을 보장해야 합니다. 최신 모델은 프레임 간의 광학 흐름을 조건으로 하는 판별기를 사용하여 이러한 시간적 일관성을 보장하였습니다. 이런
비디오 작업을 위해 모든 비익명화 파이프라인은 비디오 시퀀스에서 생성된 이미지의 시간적 일관성을 보장해야 합니다. 최첨단 비디오 번역 모델[39]은 해당 프레임 간의 optical flow를 조건으로 하는 판별기를 사용하여 시간적 일관성을 보장합니다. optical flow는 외부 신경망을 통해 계산되며, 이는 높은 게산 비용과 복잡한 프레임워크를 발생시킵니다. CIAGAN에서는 랜드마크에 대해 spline interpolation을 통해 처리를 하여 시간적 일관성을 얻고 있습니다. 따라서 CIAGAN은 동일한 프레임워크를 사용하여 이미지와 비디오에 대한 비식별화를 수행할 수 있으며, 유일한 차이는 보간이 필요하다는 점입니다.
3.3. Conditional generative adversarial networks
GAN framework
간단한 용어로, GAN은 두 개의 신경망, 즉 현실적으로 보이는 샘플을 생성하는 것을 목표로 하는 생성기 G와 실제 샘플과 생성된 샘플을 구별하는 것을 목표로 하는 판별기 D를 결합합니다. 네트워크는 적대적 방식으로 훈련되며, D는 훈련 및 생성된 예제 모두에 올바른 레이블을 할당할 확률을 최대화하도록 훈련되고, G는 D가 생성된 샘플에 대한 올바른 레이블을 예측할 확률을 최소화하도록 훈련됩니다. 즉, D는 생성된 샘플과 실제 샘플을 분리하는 방법을 학습하는 반면, G는 D를 속여서 생성된 샘플을 실제 샘플로 분류하는 방법을 학습합니다. GAN 훈련이 어렵고 많은 트릭이 필요하다는 것은 잘 알려져 있습니다. 이 작업에서는 LSGAN 손실 함수를 사용하여 CIAGAN을 훈련하기로 선택합니다.
GAN 훈련에 최소 제곱 손실 함수를 사용하는 아이디어는 간단하면서도 강력합니다. 최소 제곱 손실 함수는 올바르게 분류되었지만 여전히 실제 샘플에서 멀리 떨어져 있는 샘플도 처벌하기 때문에 가짜 샘플을 결정 경계로 이동할 수 있습니다. 이는 대부분 잘못 분류된 샘플에 불이익을 주는 교차 엔트로피 손실과 반대됩니다. 이 속성을 기반으로 LSGAN은 실제 데이터에 더 가까운 샘플을 생성할 수 있습니다. LSGAN 설정에서 판별기의 목적 함수는 다음과 같이 정의됩니다:
여기서 a와 b는 가짜 데이터와 진짜 데이터의 레이블입니다. 생성기의 손실은 다음과 같이 정의됩니다:
LSGAN은 GAN 훈련에 사용되는 다른 일반적인 손실 함수로 대체할 수 있습니다.
Conditional GAN
일반적인 GAN은 무작위 노이즈 벡터를 입력으로 생성기를 학습하는데요. CIAGAN의 경우 포즈 보존 및 시간적 일관성을 위해 생성된 얼굴을 입력 이미지의 랜드마크와 정렬해야 하며, 배경에 대한 정보도 중요합니다. 따라서 조건부 GAN 프레임워크를 사용하였습니다. 구체적으로 입력으로 랜드마크와 마스크된 이미지(배경)을 넣는 인코더-디코더 구조의 아키텍쳐를 적용하였습니다. 인코더는 랜드마크와 마스크된 이미지를 저차원 표현(병목)으로 가져와 디코더가 결합된 표현을 취하고 이를 업샘플링하여 익명화된 RGB 이미지를 생성합니다.
3.4. Identity guidance
랜드마크 등을 입력으로 하였을 때에도 모델이 빠르게 학습 데이터에 오버피팅되는 경향이 있었다고 합니다. 이렇게 될 경우 결국 원래 얼굴과 유사한 얼굴울 생성하게 되어 비식별화 목적이 사라지게 되기 때문에, 이 문제를 해결하기 위해 Identity guidance discriminator를 학습하였다고 합니다. 이 판별기는 주어진 실제 이미지에 대해 생성할 이미지의 원하는 신원을 무작위로 선택하는 역할을 합니다.
이 Identity는 One-Hot 벡터로 표현되며, 생성자의 bottleneck 부분에 입력값으로 들어가게 됩니다. 이러한 방식으로 생성기는 실제 이미지의 포즈를 유지하면서 원하는 아이덴티티의 일부 특성을 가진 얼굴을 생성하는 방법을 학습합니다. 즉, 생성된 이미지는 랜드마크 아이덴티티와 원하는 아이덴티티 모두가 적용된 이미지입니다. 여기서 생성된 이미지가 비식별화되기를 원한다면 생성된 이미지의 ID가 실제 ID와 동일하지 않아야 합니다.
신원 판별기는 Proxy-NCA loss을 사용하여 사전 훈련된 샴 신경망으로 설계되었습니다. 사전 훈련은 실제 이미지를 사용하여 수행되며, 여기서 판별자는 동일한 정체성에 속하는 이미지의 특징을 결합하도록 훈련됩니다. 신원 판별기의 목표는 생성기에 안내 신호를 제공하여 특정 신원의 표현 특징과 유사한 이미지를 생성하도록 안내하는 것입니다.
The case for multiple object tracking
특히 흥미로운 것은 가짜 신원 생성에 대한 통제입니다. 우리는 카메라에서 가져온 시퀀스(예: 여러 개의 객체 추적) 내에서 동일한 실제 사람-가짜 신원 매핑을 유지할 수 있어야 하지만 동시에 데이터의 장기 추적 및 잠재적인 오용을 피하기 위해 다른 카메라에 대한 매핑을 변경할 수 있어야 합니다. 그렇게 하기 위해, 한 사람이 한 카메라에서 다른 카메라로 이동할 때, 우리는 그 제어 벡터를 새로운 카메라로 대체하고, 그 사람에게 새로운 신원을 제공합니다. 이것은 장기 추적의 바람직하지 않은 결과 없이 카메라에서 가져온 프레임 내에서 여러 개의 객체 추적을 수행하는 간단하지만 강력한 방법입니다.
이 부분은 정확하게 이해는 안가지만 동일 카메라 내의 영상에서는 동일 신원을 그대로 유지하고, 다른 카메라의 영상에서는 새로운 신원이 유지된다는 내용으로 보이는데, 데이터가 달라지면 다시 신원이 매핑되는게 당연한게 아닌가 싶기도 하고 이해를 잘못했나 싶기도 하고 그렇습니다.
4. Experiments
Datasets
CIAGAN은 3개의 데이터셋을 사용하였습니다.
- CelebA : 데이터 세트는 10,177개의 고유한 ID로 구성된 202,599개의 얼굴 이미지입니다. 저자는 정렬된 버전을 사용하여 각 이미지가 사람의 눈 사이의 한 점에 중심을 두고 원래 얼굴 비율을 유지하면서 178 × 218 해상도로 패딩 및 크기를 조정했습니다. 각 ID에는 최대 35개의 사진이 포함됩니다. 얼굴 랜드마크는 HOG를 사용하여 추출했습니다.
- MOTS : 이 데이터셋에서는 얼굴 랜드마크를 사용하는 대신 신체 분할 마스크를 사용합니다. 데이터 세트는 1,595명의 서로 다른 사람들의 3,425개의 비디오로 구성됩니다.
- Labeled Faces in the Wild (LFW) : 이 데이터 세트는 10개로 스플릿된 6,000개의 쌍 이미지로 구성되며, 여기서 쌍의 절반은 동일한 정체성의 이미지를 포함하고 나머지 쌍은 서로 다른 정체성을 가진 이미지로 구성됩니다.
Baselines
일반적인 비식별화 기법 및 기존 모델과 비교를 진행했습니다.
- Simple Anonymization methods : 얼굴의 픽셀화, 블러 및 마스킹과의 비교를 수행했습니다.
우리는 얼굴의 픽셀화, 블러 및 마스킹을 사용하고 우리의 방법과 비교합니다. - Image Translation methods : 공식 pix2pix, CycleGAN과 비교를 진행했습니다.
- Face Replacement methods : Sota 모델과 비교를 진행했습니다.
4.1. Implementation details
저자는 랜드마크 및 얼굴 마스크에 대해 Dlib-ml 라이브러리를 사용하여 생성하였습니다. 학습 이미지는 128x128 해상도로 맞추어 훈련하였고 생성기 모델의 아키텍쳐는 U-Net입니다. identity branches의 피쳐는 bottleneck에서 연결됩니다.
판별기를 위해 identity guidance network와 동일한 아키텍쳐를 가진 표준 컨볼루젼망을 사용했고, learning rate 1e-5, Adam, 60 에포크 동안 훈련을 진행했습니다. $\beta_1, \beta_2$는 0.5, 0.9로 설정하였습니다. 모델의 훈련은 단일 GPU 기준 하루 정도 소요되었습니다. 세부적인 내용은 논문 끝의 보충 자료에서 확인할 수 있습니다.
4.2. Evaluation metrics
HOG, SSH를 통해 얼굴 감지를 수행하였고, 감지된 얼굴의 백분율을 사용하여 성능을 평가하였습니다.
재식별을 위해 Proxy-NCA를 사용하여 샴 네트워크를 훈련하였고, Inception-Resnet backbone 기반의 FaceNet을 사용하였습니다. 재식별에는 Recall@1을 사용하여 평가를 수행했습니다. 이 메트릭은 0~100 사이의 값을 가지고 있으며 0일 경우 완벽한 비식별율, 100일 경우 완벽한 식별율을 나타냅니다.
마지막으로 FID를 사용하여 정량적으로 시각적인 품질을 체크하였습니다.
4.3. Ablation Study
위의 표에서는 ID 판별기를 기본적인 샴 네트워크를 사용한 버전과, 일반적인 분류기를 사용한 버전, 세번째는 랜드마크를 입력으로 받지 않고 전체 얼굴을 입력으로 받는 버전에 대한 연구를 수행했습니다. 분류기를 변경할 경우 탐지율이 떨어지는 걸 확인할 수 있고, 랜드마크 대신 전체 얼굴을 넣을 때에도 오히려 더 낮은 점수를 보이는 걸 확인할 수 있습니다.
4.4. Quantitative results
Detection and Recognition
비식별화 결과는 높은 얼굴 탐지율과 낮은 신원 식별률이 필요한데요. 다른 비식별화 방법들에 비해 높은 탐지율과 낮은 식별률을 달성한 걸 확인할 수 있습니다.
Recognition based on landmarks
이번에는 랜드마크만을 입력으로 받았을 때에 대해 테스트를 진행해보았습니다. 랜드마크만을 식별 모델에 넣을 경우 70.7 → 30.5% 정도의 성능을 보이는데요. 비식별화를 진행한 후의 얼굴에서 랜드마크를 추출하여 식별자를 평가할 경우 1.9% 정도의 성능이 나온다고 합니다.
이 부분은 무엇을 목적으로 실험한 건지 이해가 잘 안되네요.
Are we just doing face swapping?
저자는 identity guidance network를 통해 페이스 스와핑만 이루어진것이 아닌가에 대한 확인을 진행했는데, 위의 그림과 같이 다행히도 생성된 이미지가 주어진 아이덴티티(인종 또는 성별)의 높은 수준의 특성을 취하지만 해당 아이덴티티의 실제 이미지와는 크게 다르다는 것을 확인할 수 있었다고 합니다.
4.4.1 Comparison to SOTA in de-identification
LFW 데이터에 대해 SOTA 논문과 비교를 진행했습니다. VGGFace2, CASIA-Webface에서 사전 학습된 FaceNet을 식별 모델로 사용했습니다.
평가 지표는 true acceptance rate으로 최대 0.001 비율의 거짓 양성에 대한 참 양성의 비율입니다.
실제 얼굴은 0.99 수준의 완벽한 식별률을 보이는 것을 확인할 수 있고, SOTA와 비교해 본 결과 VGGFace2에서는 0.04, CASIA에서는 0.016 정도로 더 좋은 성능을 보이는 걸 확인할 수 있습니다.
평균적으로 CIAGAN은 첫 번째 데이터 세트에서 10.5%의 비식별률을, 두 번째 데이터 세트에서 45.7%의 비식별률을 보여주면서도 99.13%의 높은 탐지율을 유지합니다. 평균 2.65%의 참 양성률은 결함이 거의 없는 시스템도 CIAGAN 처리된 데이터에서 진정한 정체성을 완전히 찾지 못할 것임을 보여줌으로써 이미지 익명화를 달성하는 데 있어 CIAGAN이 강점이 있다는 걸 확인할 수 있습니다.
4.5. Visual quality of the results
CIAGAN의 FID는 4.3에서 소개한 표와 같이 2.08 정도로 기존 방법들보다 좋은 성능을 보이고 있습니다.
또한 위의 그림과 같이 신원 판별기의 제어 벡터가 변경될 때 생성된 이미지의 다양성을 확인해 볼 수 있었습니다.
Figure 4에서는 다른 SOTA와의 시각적 성능 비교를 확인할 수 있으며
Figure 5에서는 시간적 일관성이 있다는 것을 확인할 수 있었습니다.
저자는 모든 경우에 포즈가 보존되어 뛰어난 시간적 일관성을 얻을 수 있었고, 동시에 랜드마크와 함께 작동하는 CIAGAN 버전이 전체 얼굴에서 훈련된 버전보다 더 나은 이미지를 생성한다는 것을 확인했다고 합니다.
마지막으로, Figure 6은 전신에 대한 비식별화를 실험해보았는데요. 각 행의 첫 번째 이미지는 원본 이미지로 나머지는 생성된 비식별화 이미지입니다. 자세 정도는 잘 유지하지만 색이나 신체 등에서는 잘 안되는것을 확인할 수 있습니다.
5. Conclusions and Future Work
마지막으로 저자의 결론을 정리해보도록 하겠습니다. 이 논문에서 저자는 이미지와 비디오의 얼굴 및 신체 익명화 프레임워크를 제안했습니다. 저자의 새로운 CIAGAN 모델은 조건부 생성 적대 네트워크를 기반으로 하며, 얼굴은 샴 네트워크가 제공하는 안내 신원 신호를 기반으로 익명화됩니다. 이러한 방법은 생성된 이미지에서 큰 다양성을 보여주면서 비식별화에서 최첨단을 능가한다는 것을 보여주었습니다.
제가 현재 가진 의문점은 “생성형 모델이 학습을 수행할 때 원본과 같게끔 학습을 수행할텐데, 성능이 너무 높아진다면 비식별화라고 볼 수 있을까?” 인데요. 이 논문은 이러한 문제를 Identity guidance discriminator를 사용하여 다른 신원 특징까지 함께 입력으로 받아 이미지를 생성하는 방식으로 해결하고자 했다는 점을 확인할 수 있었습니다.