
LoRA: Low-Rank Adaptation of Large Language Models
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes le
arxiv.org
최근 자연어 처리 분야에서 가장 활발한 주제는 LLM을 어떻게 자신이 원하는 특정 태스크, 또는 특정 도메인에 파인튜닝을 할 수 있을지인데요. LLM이 가진 모든 파라미터를 파인튜닝하기에는 상당히 많은 자원을 필요로 하기 때문에, 더 적은 파라미터만으로도 효율적이게 파인튜닝할 수 있는 방안에 대한 연구가 이어졌습니다. 이러한 방법들이 PEFT(Parameter-Efficient Fine-Tuning) 라는 분야라고 볼 수 있습니다. 오늘 소개할 방법은 이러한 방법들 중에 가장 인기있는 방법인 LoRA입니다. LoRA는 허깅페이스의 Peft 라이브러리에 구현되어 있어서 쉽게 사용하실 수 있습니다.
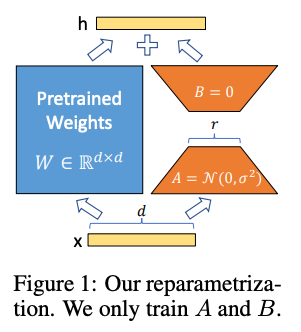
아키텍쳐는 위의 그림과 같은데요. 기존의 Pre-trained Weight와 별개의 레이어를 병렬로 구성하여 더해주는 방식으로 구현되어 있습니다. 이전에 있던 직렬 연결 방식과 달리 병렬로 연결이 되어있어서 속도 면에서도 이점이 있는 아키텍쳐입니다. 아키텍쳐의 오른쪽 추가된 레이어를 보시면 랭크를 $r$까지 줄이는 과정이 포함되있는 것을 볼 수 있는데, `Li et al. (2018a); Aghajanyan et al. (2020)` 에서 나온 학습된 over-parametrized 모델이 실제로는 낮은 차원에서 표현될 수 있다는 결론을 토대로 모델의 가중치 변화 역시 Low Rank를 가질 것이라는 가설을 통해 이러한 "Low-Rank Adaptation (LoRA)"를 구현했다고 합니다.
즉 일반적인 파인 튜닝은 모델을 계속 학습해나가면서 가중치를 변화시키는데, 이러한 가중치 변화를 기존의 가중치의 변경 없이 Low Rank 파라미터를 따로 두고 이를 학습하는 아이디어로 변형했다고 보시면 됩니다.
이 문제를 수식으로 정의해보도록 하겠습니다. 우선 기존에 가지고 있는 Pre-trained LLM을 $P_\Phi(y|x)$ 라고 정의해보겠습니다. 여기서 $\Phi$는 모델의 파라미터를 의미합니다. Full Fine Tuning에서 모델은 Pre-trained된 파라미터인 $\Phi_0$로 시작하여 계속해서 일정 변화율만큼 업데이트 되는데요. 이를 $\Phi_0 + \Delta\Phi$ 로 표현할 수 있습니다. 이 과정을 반복하며 파인튜닝을 진행하는 것인데요. 이 때 이 학습의 목적은 아래의 수식을 최대화하는것이 목적이라고 할 수 있습니다.
$$ max_{\Phi}\sum_{(x,y)\in\Z}\sum_{t=1}^{|y|}log(P_{\Phi}(y_t|x, y_{<t})) $$
쉽게 풀어쓰면 Input $x$가 주어졌을 때 가장 적절한 $y_t$가 나오게끔 파라미터 $\Phi$를 사용한 모델 $P_\Phi$를 최대화 시킨다는 내용입니다. 저자의 방식대로 $\Phi_0$를 고정시키고, 매 학습마다 업데이트 하는 부분인 $\Delta\Phi$를 새로운 파라미터인 $\Theta$를 업데이트 하는 것으로 변경하면, 다시 말해 $\Delta\Phi=\Delta\Phi(\Theta),\ ( |\Theta|<|\Phi_0|)$로 변경한다면 아래와 같은 수식으로 변경할 수 있습니다.
$$ max_{\Theta}\sum_{(x,y)\in\Z}\sum_{t=1}^{|y|}log(p_{\Phi_0+\Delta\Phi(\Theta)}(y_t|x, y_{<t})) $$
Low Rank 파라미터를 학습시키는 걸로 가중치 업데이트를 대체하겠다는 수식입니다.
이러한 LoRA 방법론의 Forward Pass를 행렬로 표현하면 다음과 같이 표현할 수 있습니다.
$$ h = W_0x + \Delta Wx = W_0x + BAx $$
이 때의 $B$는 $d\times r$, $A$는 $r \times k$ 행렬, $W_0$는 $d \times k$ 입니다. 학습을 시작할 때에는 $A$는 랜덤 가우시안 초기화를, $B$는 0으로 초기화를 시킨다고 합니다. 이렇게 새로운 Low Rank 가중치를 업데이트하는 구조를 가진 덕에 새로운 태스크를 하고자 할 때 LoRA 가중치만 해당 태스크에 맞춰 변경하는 식으로 빠른 변경이 가능해졌습니다.
즉 LoRA는 기존의 가중치를 업데이트 하지 않고 새로운 파라미터만 업데이트하면 되다보니 기존 Full Fine tunning보다 훨씬 적은 리소스를 필요로 하게 되었으며, LoRA로 학습한 파라미터만 다른 태스크에 맞춰 바꿔끼며 원하는 태스크의 작업을 할 수 있게 되었습니다. 두 번째 장점의 경우 Stable Diffusion에서 특히 자주 사용되는 것으로 알고 있는데, 다양한 그림 작업 태스크에 대해 LoRA를 통해 학습한 후 LoRA 가중치만 바꿔끼며 원하는 화풍 등을 적용시키는 것으로 알고 있습니다.
LoRA는 트랜스포머의 셀프 어텐션 레이어에 적용이 되는데요. q,k,v,o 각각에 대해 실험해 본 결과 (q,k) 보다는 (q,v)가 성능이 좋았다고 하며, 모두 적용하는 것이 가장 효과적이었다고 설명하고 있습니다. o는 멀티헤드어텐션의 가중치를 의미
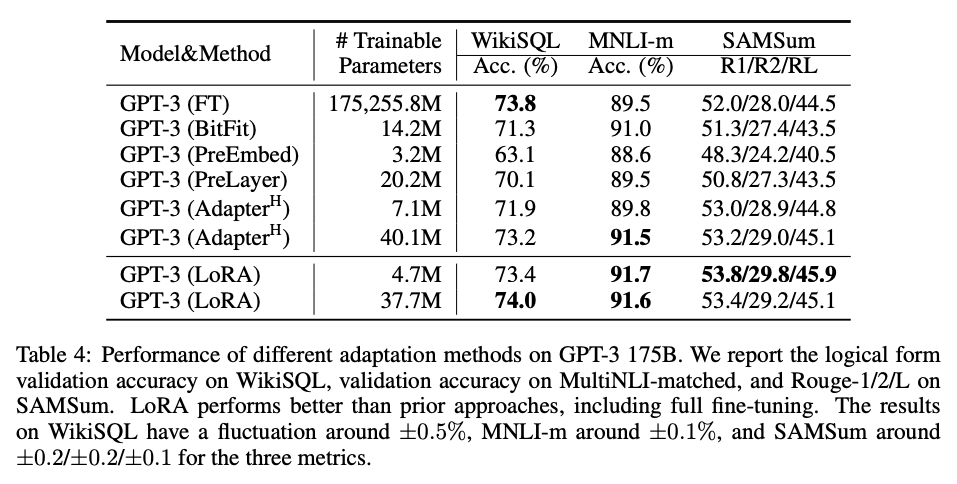
GPT-3의 적용 결과를 보면 학습 가능한 파라미터가 적음에도 Full Fine Tunning과 비슷할 정도로 상당히 좋은 성능을 보임을 알 수 있습니다.
참고로 Alpaca 학습에 LoRA를 많이 사용하고 있는데요. Alpaca 개발진의 블로그 글을 읽어보면 LoRA를 사용할 경우 학습 중에 사용하는 총 메모리 공간을 112GB에서 약 28GB까지 줄일 수 있다고 합니다. 즉 A100(vram 80GB) 2대는 필요했던 파인튜닝 과정이 V100(vram 16GB) 2대 정도로도 충분히 돌릴 수 있다는 장점을 가지고 있습니다.
간단하다면 간단할 수 있는 아이디어를 통해 적은 파라미터 만으로도 LLM을 높은 수준으로 파인튜닝할 수 있는 기술이 생긴 것 같습니다. 이 기술의 중요성은 유출되었다는 구글 내부 문서에서 확인할 수 있는데요. 내부 문서에서는 구글 LLM의 가장 큰 적이 OpenAI가 아닌 오픈소스 AI라고 생각하고 있고, 그 중 가장 강력한 기술이 LoRA라고 언급하고 있습니다.

Google "We Have No Moat, And Neither Does OpenAI"
Leaked Internal Google Document Claims Open Source AI Will Outcompete Google and OpenAI
www.semianalysis.com