
LLaMA: Open and Efficient Foundation Language Models
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, witho
arxiv.org
올해 Meta AI에서 공개한 LLaMA: Open and Efficient Foundation Language Models 를 리뷰해보도록 하겠습니다.

최근 들어 나오고 있는 대규모 언어 모델(LLM)은 거대한 말뭉치로 학습을 함으로써 상당히 좋은 생성 능력을 보여주고 있습니다. 다만 이러한 대규모 언어 모델의 경우 추론에 대해 상당히 많은 자원과 시간이 소비됩니다.
만약 대규모 언어 모델을 서비스하고자 한다면, 아마 기업에서 선호하는 모델은 (동일 성능일 때) 훈련 시간이 짧은 모델이 아닌, 추론 시간이 짧은 모델일 것입니다. LLaMA는 이렇게 추론 속도를 높이기 위해 학습 시간을 늘리더라도 추론 시간은 줄이는 방법을 사용했습니다.
따라서 이 논문은 모델의 크기는 줄이면서도, 일반적으로 사용되는 것보다 더 많은 토큰을 학습함으로써 학습 시간은 고려하지 않고 추론 시간을 줄이고자 했습니다. 예를 들어 LLaMA-13B는 GPT-3보다 대부분의 벤치마크에서 우수한 성능을 발휘하며, 그 크기는 10배 작다고 합니다.
큰 규모의 모델인 65B 매개변수 모델도 Chinchilla나 PaLM-540B와 같은 최고의 대형 언어 모델과 경쟁력이 있다고 하는데요. 이 때의 장점은 Chinchilla, PaLM 같은 모델들과 달리 공개적으로 이용 가능한 데이터만 사용했음에도 좋은 성능을 보였다는 것입니다.
그럼 이 논문을 한번 살펴보도록 하겠습니다.
이 논문의 제일 좋은 점은 이렇게 좋은 성능의 LLM인 LLaMA를 오픈소스로 공개했다는 점인데요. 다만 가중치는 따로 공개하지는 않았고 신청을 하면 준다고 합니다. 참고로 토렌트에 가중치파일이 돌아다닌다고 합니다. 😱
-> 현재는 LLaMA2를 완전공개한 상황입니다. 이전에 쓴 글이라 이런 내용이 적혀있을 수 있습니다.
Pre-training Data
LLaMA의 프리트레이닝에 사용된 데이터와 사용된 전처리 방법은 다음과 같습니다. 이 내용은 번역 그대로 놔두도록 하겠습니다.
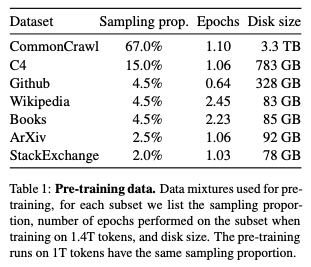
English CommonCrawl [67%]
2017년부터 2020년까지의 다섯 개의 CommonCrawl 덤프를 CCNet 파이프라인 (Wenzek et al., 2020)으로 전처리합니다. 이 과정에서 중복된 데이터는 제거되며, fastText 선형 분류기를 사용하여 비영어 페이지를 제거하기 위한 언어 식별 작업과 n-gram 언어 모델을 사용하여 저품질 콘텐츠를 필터링합니다. 또한, Wikipedia의 참조 페이지와 무작위 샘플 페이지를 구분하는 선형 모델을 훈련하고, 참조로 분류되지 않은 페이지는 제외합니다.
C4 [15%]
다양한 전처리된 CommonCrawl 데이터셋을 사용하는 것이 성능을 개선시킨다는 것을 실험적으로 확인했습니다. 따라서 공개적으로 이용 가능한 C4 데이터셋 (Raffel et al., 2020)을 데이터에 포함시켰습니다. C4의 전처리에도 중복 제거 및 언어 식별 단계가 포함되어 있습니다. CCNet과의 주요 차이점은 주로 문장부호의 존재 여부나 웹페이지의 단어와 문장 수 등과 같은 휴리스틱을 기반으로 한 품질 필터링입니다.
Github [4.5%]
Google BigQuery에서 제공하는 공개적으로 이용 가능한 GitHub 데이터셋을 사용합니다. Apache, BSD, MIT 라이선스에 따라 배포된 프로젝트만 사용합니다. 또한, 행 길이나 영숫자 문자의 비율과 같은 휴리스틱을 기반으로 저품질 파일을 필터링하고, 정규 표현식을 사용하여 헤더와 같은 보일러플레이트를 제거합니다. 마지막으로, 정확한 일치를 통해 결과 데이터셋에서 중복을 제거합니다.
Wikipedia [4.5%]
2022년 6월부터 8월까지의 Wikipedia 덤프를 추가합니다. 이는 라틴 문자 또는 키릴 문자 스크립트를 사용하는 20개 언어(bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk)를 포함합니다. 데이터를 처리하여 하이퍼링크, 주석 및 기타 서식 관련 보일러플레이트를 제거합니다.
Gutenberg and Books3 [4.5%]
훈련 데이터셋에는 두 개의 도서 말뭉치가 포함됩니다. 퍼블릭 도메인에 속하는 Gutenberg 프로젝트의 도서와 대규모 언어 모델을 훈련하기 위한 공개적으로 이용 가능한 데이터셋인 ThePile의 Books3 섹션(Gao et al., 2020)을 포함합니다. 도서 수준에서 중복을 제거하고, 90% 이상의 내용이 겹치는 도서를 제거합니다.
ArXiv [2.5%]
arXiv 라텍스 파일을 처리하여 과학 데이터를 데이터셋에 추가합니다. Lewkowycz et al. (2022)을 따라 첫 번째 섹션 이전의 모든 내용과 레퍼런스 목록을 제거합니다. 또한 .tex 파일에서 주석을 제거하고, 사용자가 작성한 인라인 정의와 매크로를 확장하여 논문 간의 일관성을 높입니다.
Stack Exchange [2%]
다양한 도메인을 다루는 고품질 질문과 답변 웹사이트인 Stack Exchange의 덤프를 포함합니다. 28개의 가장 큰 웹사이트의 데이터만 유지하고, 텍스트에서 HTML 태그를 제거하고, 답변을 점수에 따라 (높은 점수부터 낮은 점수 순서로) 정렬합니다.
Tokenizer
우리는 bytepair encoding (BPE) 알고리즘(Sennrich et al., 2015)을 사용하여 데이터를 토큰화합니다. 이때, 모든 숫자를 개별 숫자로 분리하고, 알 수 없는 UTF-8 문자를 분해하기 위해 바이트로 대체합니다. 이 과정은 SentencePiece (Kudo and Richardson, 2018)의 구현을 사용합니다.
전반적으로, 전체 훈련 데이터셋은 토큰화 후 약 1.4조 개의 토큰을 포함합니다. 대부분의 훈련 데이터에서는 각 토큰이 훈련 중에 한 번만 사용되지만, Wikipedia와 Books 영역에서는 약 두 번의 epoch을 수행합니다.
Architecture
LLaMA의 아키텍쳐는 트랜스포머를 기반으로 합니다. 이후 다양한 모델에서 제안한 다양한 개선 사항을 활용했습니다.
Pre-normalization
GPT-3에서 사용된 방법으로, 트랜스포머의 각 서브레이어의 출력을 정규화하는 기존 방법 대신 입력을 정규화하는 방법을 사용합니다. 여기서 사용하는 정규화 함수는 RMSNorm입니다.
조금 더 적어보면, 원래 트랜스포머는 $Layernorm(x + Sublayer(x))$ 로 정규화 하는데요. 이 서브레이어에 들어가기 전 x값을 RMSNorm을 통해 정규화한다고 보시면 됩니다. LLaMA의 코드를 보면 다음과 같이 구현되어 있습니다.
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return outforward의 h 계산식을 보시면 입력에 attention_norm을 먼저 취하는 것을 확인할 수 있습니다.
SwiGLU activation function
PaLM에서 사용된 방법으로, ReLU를 SwiGLU로 변경하여 사용했습니다. 다만 LLaMA에서는 PaLM의 $4d$ 차원과 달리 ${2\over{3}}4d$ 차원을 사용했습니다.
SwiGLU는 Swish + GLU로 간단하게 공식만 확인해보도록 하겠습니다.
$$
SwiGLU(x,W,V,b,c,β)=Swish_β(xW+b)⊗(xV+c)
$$
여기서 Swish는 다음과 같습니다.
$$
Swish_β(x)=xσ(βx)
$$
조금 더 자세한 내용은 아래 링크에서 확인할 수 있습니다. https://velog.io/@tobigs-nlp/PaLM-Scaling-Language-Modeling-with-Pathways-1
디멘션에 대해서는 PaLM 또는 SwiGLU 논문을 읽어봐야 이해할 수 있을 것 같네요.
Rotary Embeddings
GPTNeo에서 사용된 방법으로, absolute positional embedding을 제거하고 rotary positional embeddings (RoPE)를 사용했습니다.
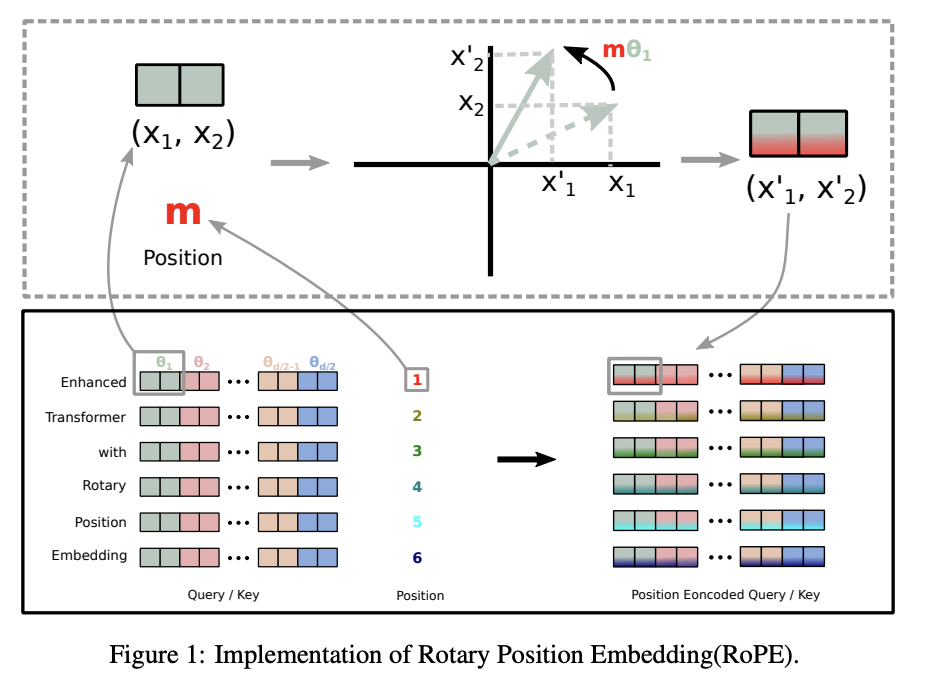
위의 그림과 같은 방식이라고 하는데요. 느낌만 보면 어텐션 계산시에 적용하는 것 같아 보입니다.
이것도 나중에 논문(https://paperswithcode.com/method/rope)을 읽어봐야 정확하게 알 것 같습니다.
Optimizer
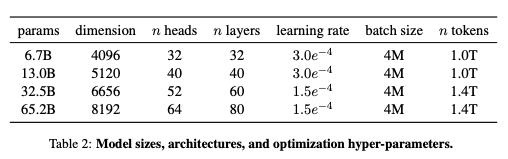
옵티마이저는 AdamW를 사용했으며, 하이퍼파라미터는 다음과 같습니다. $\beta1 = 0.9, \beta2 = 0.95$.
Cosine learning rate schedule 방법을 사용하여 학습을 스케쥴링하였고, 이를 사용하여 최종 learning rate는 최대의 10%가 되게끔 조정했습니다.
weight decay는 0.1로 설정하고 gradient clipping은 1.0으로, warmup step은 2000을 사용했으며 초기 learning rate와 batch size는 위의 표에서 확인할 수 있습니다.
코사인 어널링 역시 나중에 한번 정리해보도록 하겠습니다.
Efficient implementation
LLaMA의 훈련 속도를 향상시키기 위해 다양항 최적화 방법을 사용했습니다.
첫째로, 멀티 헤드 어텐션의 효율적인 구현을 사용했습니다. 이 방법은 어텐션 가중치를 적용하지 않고, 마스크된 키/쿼리 스코어를 계산하지 않는 방식인데요. xformers 라이브러리에서 사용할 수 있습니다.
또한 역전파 중에 다시 계산되는 활성화량을 체크포인팅 방법을 통해 줄였습니다. 이 방법은 pytorch autograd에 의존하지 않고, 역전파 함수를 수동으로 구현함으로써 달성했다고 합니다.
또한 모델과 시퀀스 병렬성을 사용하여 메모리 사용량을 줄이고, 활성화값의 계산과 GPU 간 통신을 가능한 한 겹쳐서 수행하는 방법을 사용했습니다.
이러한 최적화 결과 65B 파라미터 모델을 훈련하는 경우, 80GB의 RAM을 가진 2048개의 A100 GPU에서 약 380 토큰/초의 처리 속도를 보입니다. 이는 1.4조 토큰을 포함한 데이터셋을 대상으로 훈련하는 데 약 21일이 걸린다는 의미라고 볼 수 있습니다.
참고로 모델 훈련에 든 비용은 다음과 같다고 합니다.
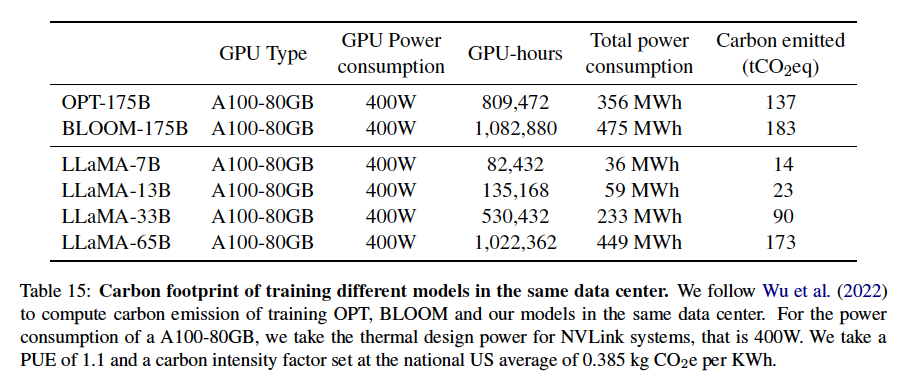
Result
LLaMA에서는 zero-shot과 few-shot 태스크를 고려했습니다. 각각은 다음과 같습니다.
- zero shot : 태스크에 대한 텍스트 설명과 테스트 예제를 제공합니다. 모델은 답변을 생성하거나 제안된 답변을 순위화합니다.
- few shot : 태스크에 대한 (1-64)가지 예제와 테스트 예제를 제공합니다. 모델은 이 텍스트를 입력으로 받아 답변을 생성하거나 순위화합니다.
LLaMA의 평가는 free-form generation tasks 와 multiple choice tasks 를 통해 평가했습니다.
논문에는 다양한 주제의 데이터에 대해 테스트를 진행했는데요. 저는 제로샷의 결과만 확인하고 다음으로 넘어가도록 하겠습니다. 만약 다른 테스트가 궁금하다면 논문의 3 챕터를 확인해주세요.
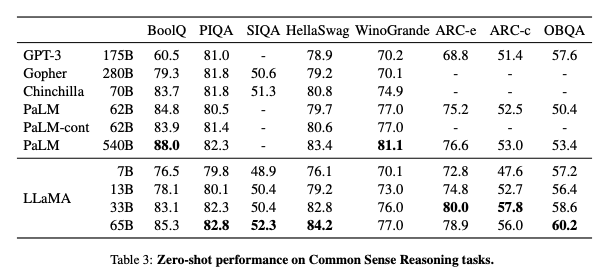
제로샷의 성능이 GPT-3과 비교해서 상당히 좋다는 걸 확인할 수 있습니다. 약 7B 모델만 써도 GPT-3와 비슷한 수치가 나오네요!
Instruction Finetuning
이 섹션에서는 간단한 Instruction Finetuning이 빠르게 성능을 향상시킬 수 있다는 것을 보여줍니다. 파인튜닝 이전의 LLaMA-65B는 이미 기본적인 지시사항을 따를 수 있지만, 매우 적은 양의 파인튜닝을 통해 성능을 더욱 향상시킬 수 있습니다.
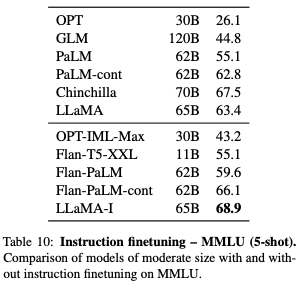
다만 이 Instruction Finetuning이 이 논문의 포커스는 아니기 때문에, 단일 실험만 수행해보았다고 합니다. 여기서 실험한 Instruction 모델의 이름은 LLaMA-I 입니다.
아래 테이블은 Instruction Finetuning을 수행한 LLaMA-I 의 비교표인데요. 기존 LLaMa-65B보다 성능이 오른 것을 확인할 수 있습니다. 다만 표에는 없지만 가장 최신 기술인 GPT code-davinci-002의 77.4보다는 낮습니다.
5,6 섹션은 편향 정보, CO2 배출량 등과 관련된 내용으로 이 페이지에서는 따로 다루지 않았습니다. 7 섹션인 Related work도 따로 정리하지 않겠습니다.
Conclusion
마지막으로 이 논문을 정리해보도록 하겠습니다. 본 논문에서 공개한 LLaMA는 오픈소스임에도, LLaMA-13B가 GPT-3(175B)보다 우수한 성능을 발휘할 만큼 성능이 좋습니다.
더 큰 모델인 LLaMA-65B는 Chinchilla-70B 및 PaLM-540B와 비교가 가능한 경쟁력을 가지고 있습니다. 이전 연구들과 달리 이 논문에서 사용한 데이터셋은 완전히 오픈된 데이터들로, 이러한 데이터들을 사용함에서 좋은 성능을 달성할 수 있다는 것을 확인할 수 있었습니다.
저자는 이러한 모델을 공개함으로써 편향 등의 문제를 함께 노력해보고 싶다고 합니다.